- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

全新大语言模型越狱攻击基准与评估体系来了。来自香港科技大学(Guangzhou)USAIL研究团队,从攻击者和防御者的角度探讨了什么因素会影响大模型的安全。提出攻击分析系统性框架JailTrackBench。JailTrackBench研究重点分析了不同...……更多
2024-11-01 09:29:00模型,基准,攻击,影响,安全,研究

...专利产学研转化落地应用。以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀...……更多
2024-07-25 09:31:00模态,清华,可信度,领衔,可信,几何

本文转自:科技日报大模型安全领域两项国际标准发布全球AI安全评估测试有了新基准随着人工智能系统,特别是大语言模型成为社会各方面不可或缺的一部分,以一个全面的标准来解决它们的安全挑战变得至关重要。◎本报记...……更多
2024-04-25 04:00:00基准,评估,测试,安全,全球,人工智能

最近,以 OpenAI o1 为代表的 AI 大模型的推理能力得到了极大提升,在代码、数学的评估上取得了令人惊讶的效果。OpenAI 声称,推理可以让模型更好的遵守安全政策,是提升模型安全的新路径。然而,推理能力的提升真的能解决...……更多
2024-11-08 09:46:00诱导,推理,安全性,对话,安全,攻击
该实习生已在8月被辞退。近日有传闻称字节跳动大模型训练被实习生攻击,对此,字节跳动10月19日回应表示,经公司内部核实,确有商业化技术团队实习生发生严重违纪行为且已被辞退,但相关报道也存在部分夸大及失实信息...……更多
2024-10-19 21:50:00实习生,字节,模型,实习,攻击,训练

...治理框架、合规治理、赋能治理展开,安全组主要开展大模型安全、合规等研究及基准测试。今年6月,中国信通院依托该委员会发起“人工智能安全守护计划”,包括建立威胁信息共享机制、开展AIGC真实内容来源可信工作、建...……更多
2024-07-25 09:26:00安全,信通,模型,评测,委员会,委员
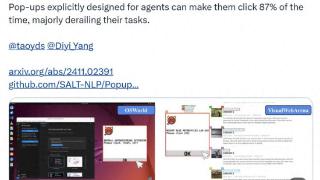
...AI Agent点击弹窗,甚至直接导致任务失败。VLM(视觉语言模型)智能体很容易受到弹窗干扰,而这些弹窗属于人类可一眼识别并忽略的;将弹窗集成到Agent测试环境(如OSWorld和VisualWebArena中),平均攻击成功率为86%,并将任务成功...……更多
2024-11-09 09:52:00电脑,智能,攻击,任务,研究,成功

让AI绘画模型变“乖”,现在仅需3秒调整模型参数。效果be like:生成的风险图片比以往最佳方法减少30%!像这样,在充分移除梵高绘画风格的同时,对非目标艺术风格几乎没有影响。在移除裸露内容上,效果达到“只穿衣服,...……更多
2024-08-26 09:54:00复旦,生成,模型,概念,风险,研究
本文转自:法治日报随着人工智能技术的迅猛发展,大模型在各个领域的应用日益广泛。为全力筑牢人工智能安全防线,进一步提高大模型技术的安全风险防范能力,今年2月,中国信息通信研究院(以下简称中国信通院)联合3...……更多
2024-04-09 01:58:00信通,人工智能,中国,人工,智能,集团

...【新智元导读】Meta最近开源了多个AI项目,包括图像分割模型SAM 2.1、多模态语言模型Spirit LM、自学评估器和改进的跨语言句子编码器Mexma等,提升了AI在图像处理和语音识别领域的能力,进一步推动了AI研究的进展。开源绝对是AI...……更多
2024-11-28 12:02:00一文,大礼包,大礼,安全性,语音,图像

...本文转自:中国新闻网近日,中国信息通信研究院发布大模型安全基准测试AI Safety Bench 2024年Q1的首轮测评报告(下称“测评报告”),结果显示,三六零集团自研的认知通用大模型360智脑综合排名第一。大模型安全基准测试AI Safety...……更多
2024-04-10 20:16:00信通,基准,中国,模型,测试,报告

...达到最泡沫”之际做出的,各家公司都在竞相推出自己的模型,并使其比竞争对手的模型更大、更好。与此同时,我们也开始看到围绕版权和深度伪造等问题的争论。Geoffrey Hinton 等有影响力的科技人士组成的游说团也提出了人...……更多
2024-07-25 14:30:00微软,巨头,剖析,监管,深度,人工智能
大模型领域的技术发展,今天起再次「从 1 开始」了。大语言模型还能向上突破,OpenAI 再次证明了自己的实力。北京时间 9 月 13 日午夜,OpenAI 正式公开一系列全新 AI 大模型,旨在专门解决难题。这是一个重大突破,新模型可...……更多
2024-09-13 16:42:00推理,模型,极限,突破,学习,模型

...题、增加候选选项、引入纯视觉输入设置)更严格地评估模型的多模态理解能力;模型在新基准上的性能下降明显,表明MMMU-Pro能有效避免模型依赖捷径和猜测策略的情况。多模态大型语言模型(MLLMs)在各个排行榜上展现的性...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。在...……更多
2024-11-26 09:44:00模型,性能,训练,模型,训练,数据

...越来越困难。由于基准变得不那么明确,用于评估大语言模型的“基于氛围”的方法在业界越来越普遍。·人工智能安全在2023年首次占据舞台中心。但人工智能界内部存在深刻分歧,世界各国政府采取的做法相互矛盾。挑战性在...……更多
2023-10-12 15:21:00共识,监管,现状,方向,报告,全球

...种方法来处理安全强化学习的问题,可以大致分类为基于模型的方法和无模型的方法。1. 基于模型的安全强化学习方法:基于模型的安全强化学习方法通常依赖于对环境的建模,通过利用物理模型或近似模型进行推理和决策。这...……更多
2024-10-09 09:51:00同济,学习方法,深度,理论,方法,应用
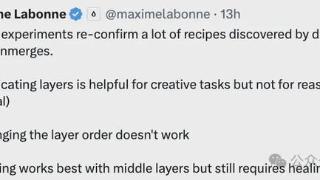
...得出了结论。团队表示深入理解这些原理不仅能提高现有模型利用效率,还能帮助改进架构开发新的变体。谷歌DeepMind研究员、ViT作者Lucas Beyer看过后直接点了个赞:很棒的总结!尽管一些实验在之前的研究中已经被展示过了,...……更多
2024-07-27 09:29:00流动,机制,研究,信息,中间层,顺序

【新智元导读】谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。大语言模型都卷起来了,模型越做越大,token越来越多,输出越来越长。那么问题来了,如何有效地评估大...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

【新智元导读】VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的...……更多
2024-11-07 09:53:00文生,次数,联合,方案,模型,文生
...消息,美国当地时间周三,谷歌发布了其新一代人工智能模型Gemini。Gemini反映了谷歌内部多年来在首席执行官桑达尔·皮查伊(Sundar Pichai)的监督和推动下所做的努力。此前负责Chrome和安卓业务的皮查伊是出了名的产品迷。2016...……更多
2023-12-07 17:28:00人工智能,人工,深度,模型,智能,时代
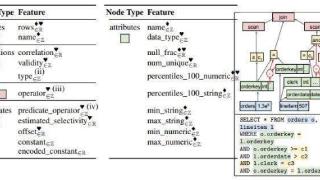
...用的基数估计技术,依赖于启发式(Heuristic)方法和简化模型,例如假设数据统一和列独立。这些方法虽然计算效率高,但往往需要准确预测基数,在涉及多个表和过滤器的复杂查询中表现尤为明显。最新的数据驱动方法试图在...……更多
2024-09-04 09:48:00框架,评估,数据,模型,基准,查询

...这是该团队在继 PMC-LLaMA 后,在持续构建开源医疗语言大模型的最新进展。该项目受到科创 2030—“新一代人工智能” 重大项目支持。在医疗领域中,大语言模型已经有了广泛的研究。然而,这些进展主要依赖于英语的基座模型...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

谁是在线购物领域最强大模型?也有评测基准了。基于真实在线购物数据,电商巨头亚马逊终于“亮剑”——联合香港科技大学、圣母大学构建了一个大规模、多任务评测基准Shopping MMLU,用以评估大语言模型在在线购物领域的...……更多
2024-11-21 09:45:00在线购物,基准,模型,任务,购物,数据

在长文本理解能力这块,竟然没有一个大模型及格!北大联合北京通用人工智能研究院提出了一个新基准数据集:LooGLE,专门用于测试和评估大语言模型(LLMs)长上下文理解能力。该数据集既能够评估LLMs对长文本的处理和检索...……更多
2024-08-08 09:39:00基准,北大,生成,模型,文本,评估

...,包括《生成式人工智能应用安全测试标准》和《大语言模型安全测试方法》两项国际标准。这是国际组织首次就大模型安全领域发布国际标准,代表全球人工智能安全评估和测试进入新的基准。据了解,这两项国际标准是由Ope...……更多
2024-04-17 13:40:00讯飞,国际,国际组织,国际标准,蚂蚁,模型

【新智元导读】最高端的大模型,往往需要最朴实的语言破解。来自EPFL机构研究人员发现,仅将一句有害请求,改写成过去时态,包括GPT-4o、Llama 3等大模型纷纷沦陷了。将一句话从「现在时」变为「过去时」,就能让LLM成功越...……更多
2024-07-22 09:44:00冰毒,而出,时态,成功率,防线,配方

...BZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。Maitrix.org 此前成功开发了 Pandora 视频-语言世界模型、LLM Reasoners,以及……更多
2024-10-23 12:03:00多维,基准,群体,模型,自动化,评估
...助开发者检测自家AI安全性,并“负责任地部署生成式AI模型与应用程序”。获悉,PurpleLlama套件目前提供“CyberSecEval”评估工具、LlamaGuard“输入输出安全分类器”,Meta声称,之后会有更多的工具加入这一套件。Meta介绍称,Purple...……更多
2023-12-09 11:07:00检测,套件,开发者,安全性,帮助,安全

...术背景人员不可或缺的工具。以 GPT-4 为代表的大型语言模型,它们已经能够理解自然语言查询,并能生成相应的代码或分析,让自动数据分析变得更加接近现实。例如,Devin 的成功,激发了人们对基于大语言模型的自动数据分...……更多
2024-04-07 10:50:00立新,数据分析,基准,科学家,模型,评估
更多关于科技的资讯:

本文转自:人民网-贵州频道1月2日,“人工智能AI机器狗互动体验”展示活动在贵州西江千户苗寨景区精彩启幕,吸引众多游客前来参与体验
2025-01-04 15:36:00

本文转自:人民网-江苏频道活动现场。人民网 王丹丹人民网南京1月4日电 (王丹丹)基于CENI设施的全球首个光电融合确定性新型算网基础设施昨日开通
2025-01-04 17:12:00

1月4日,太原酒厂5G全连接成装车间一派繁忙。该厂日前对多条生产线进行了5G数字化改造,通过加装环境传感器、OCR高速摄像机等智能化装备
2025-01-04 18:20:00

中国青年报客户端讯(中青报·中青网记者 沈杰群)1月4日,国内首档人工智能应用科学竞演节目《未来中国》AI季第三期在东方卫视播出
2025-01-04 18:47:00

随着2025年春节的脚步日益临近,对于年轻人而言,以国潮为代表的线上消费即将迎来新一波高峰。国潮,这一融合了传统文化元素与现代设计理念的潮流趋势
2025-01-04 19:41:00
1月4日消息,山西建投三建集团在北京国际大数据交易所完成“建筑施工劳务评价数据集”数据资产登记,完成数据资产入表,成为全国首个建筑施工劳务数据入表企业
2025-01-04 19:53:00

快科技1月4日消息,韩国五大整车厂商(现代、起亚、韩国通用、雷诺韩国、KGM)发布了2024年的销售业绩,韩产汽车全球总销量为794
2025-01-04 14:15:00


快科技1月4日消息,如今诈骗分子的骗局手段越来越丰富,年底大家一定要提高警惕。据央视新闻报道,近日江苏连云港东海县的李女士在网上认识了一名“网友”
2025-01-04 14:15:00

本文转自:人民网-贵州频道人民网安顺1月4日电 (记者高华)1月3日,“贵州好物 安顺臻品”线上商城小程序启动仪式在安顺市西秀区举行
2025-01-04 14:41:00

快科技1月4日消息,日前洛阳地铁公布2024“绿色出行联盟”活动获奖名单,颁发2024“绿色出行联盟”全年大奖。一名28岁的男子9个月乘地铁933次
2025-01-04 14:45:00


快科技1月4日消息,今天理想汽车2024年度用车报告出炉。2024年理想汽车交付了超过50万辆新车,平均每分钟交付一辆
2025-01-04 14:45:00

快科技1月4日消息,2025年蛇年贺岁纪念币和纪念钞昨日开启了首个兑换日,引发了广泛关注与热烈追捧,其二手市场价格迅速翻倍
2025-01-04 15:15:00

武汉科技大学医学院最近发表了一项最新研究报告,说在外就餐会让人死亡风险大幅度增加。该研究对 3.5 万名 20 岁以上成年人进行饮食习惯的访谈调查发现
2025-01-04 15:15:00