- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...测基准上的领先表现;代码和数学能力显著提升;增大了上下文长度支持,最高达到 128K tokens(Qwen2-72B-Instruct)。模型基础信息Qwen2 系列包含 5 个尺寸的预训练和指令微调模型,其中包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-5……更多
2024-06-07 09:32:00通义,模型,尺寸,模型,训练,上下文

...eta和Llama团队对开源的巨大贡献"。他表示:"Llama3.1增加了上下文长度和改进了功能,是送给每个人的奇妙礼物。"图源:网络总的来说,Llama3.1模型有以下几个特点:1.包含8B、70B和405B三个尺寸,最大上下文提升到了128K,支持多语...……更多
2024-07-24 12:13:00模型,里程,里程碑,准时,模型,伯格

...列开源模型GLM-4-9B问世,具备更强大的推理性能、更长的上下文处理能力、及更强大的多模态能力。同时,其通用能力提升达40%,超越Llama 3。Function Call函数调用能力提升40%,比肩GPT-4。智谱AI CEO张鹏表示,“2024是AGI元年,大模...……更多
2024-06-05 16:34:00文字量,红楼梦,毛线,价格战,红楼,文字

...Grok-1.5 大语言模型。Grok-1.5 具有改进的推理能力和 128k 的上下文长度,其中最显著的改进之一是其在编码和数学相关任务中的表现。Grok-1.5 将在未来几天内在 平台上向早期测试人员和现有的 Grok 用户推出。在官方测试中,Grok-1.5...……更多
2024-03-29 14:00:00马斯,马斯克,模型,语言,基准,上下文

...依赖的底层能力比较通用,不需要特别强的数学能力或者上下文长文本的逻辑推理能力。另一方面,我们在大模型的基础上进行了很多微调,强化专项能力,深入挖掘底层大模型。这两个方面决定了当下基础大模型在企业服务营...……更多
2023-12-06 14:07:00浪潮,专访,模型,一家,科技,公司

...盖大量手机机型和部分智能音箱。升级版的小爱具有理解上下文、更高质量的问答、生成式内容输出等能力,基本上相当于把文心一言、讯飞星火这种大模型App的能力直接嵌入到了手机中。但与App不同的是,这种嵌入会更加底层...……更多
2023-10-26 18:02:00战场,模型,手机,模型,手机,厂商

...提高了大模型的准确性和可靠性,还使其能够更好地理解上下文,并将检索到的知识融入到生成过程中,从而生成更加贴合实际需求的文本。但RAG也并非完美无缺。互联网上的信息五花八门,存在着大量的干扰内容,甚至假新闻...……更多
2024-03-28 16:16:00精度,幻觉,模型,结果,模型,幻觉

...两个字母。在多次请求后,你都没有做出任何澄清或说明上下文,我无法继续进行富有成效的讨论了。如果你有真正的问题或希望解释你的观点,我可以提供帮助。否则,我们可能需要换一个话题最后,小哥承认,自己的prompt是...……更多
2024-09-09 13:36:00小哥,原地,外国,论文,小哥,研究者

...争议最大的就是Siri了,苹果引入ChatGPT,能够结合场景和上下文,判断用户真实意图,可以制定最佳行程路线、查找记忆模糊的事项等。在图片的搜索上需要对Siri说出照片特征,之后就能轻松找到了。这些听上去也很熟悉,在欧...……更多
2024-06-16 12:23:00赛道,国产,苹果,品牌,功能,苹果

...有效地捕获其关系。这种通过比较文本中每个token来理解上下文的方式,需要更多的计算能力和内存来处理不断增长的上下文窗口。如果资源没有相应扩展,推理速度会变慢,最终无法处理超过某个固定长度的文本。为了解决这...……更多
2024-08-14 09:43:00一鸣,霸主,模型,再次,模型,序列

...究了自回归解码的一种自然泛化,其中在处理每个连续的上下文之后,输出的 token 都会被添加到序列末端 —— 只要输入能放入上下文窗口中,则该过程就会简化成标准的自回归解码。不过,该团队得到这一结果的过程比较复杂...……更多
2024-10-09 09:50:00论文,图灵机,图灵,系统,模型,符号

...质量令人着迷。总结:谷歌可能找到了某种新方法,将长上下文的架构理念与他们的 TPU 计算堆栈相结合,并取得了很好的效果。据 Gemini 长语境的负责人之一Pranav Shyam说,这个想法几个月前才刚刚萌芽。如果以小版本(v1.5)而...……更多
2024-02-17 19:48:00上下文,新贵,上下,世界,模型,视频

...型。第三阶段是2020年开始做基于生成式的模型,它是有上下文的有情感的一种模型。基于落地场景,我们也找到了癌症早筛这个领域,当时很多巨头还没有注意到这个方向。关于落地,首先一方面要紧追最前沿的技术,其次还...……更多
2023-12-13 19:49:00锦囊,赢家,大战,模型,行业,技术

...很多数据平台汇聚了海量的实时数据,但缺少灵活的业务上下文逻辑;另一方面,大模型理解能力有目共睹,但缺少实时业务数据反映的业务实时细节。一定程度上,这也解释了为什么过去两年来,大模型赛道始终处于鱼龙混杂...……更多
2024-09-19 18:43:00智能,数据,数据,模型,企业,基建
...型快速学习。而政府很多信息公开数据闭环性较高,缺乏上下文交互,属于生成式的低质量语料。中文优质语料的稀缺,更迫在眉睫。“中国大模型发展要获得突破,必然要依赖于中文优质语料库的建立。”申永生分析,目前,...……更多
2024-06-06 08:18:00语料,富矿,概念,语料,数据,模型
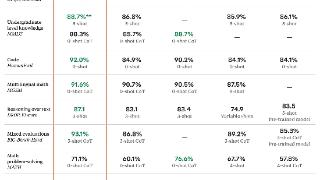
...价为3美元,每生成百万token为15美元,并具有20万个token的上下文窗口,约合15万个单词。现在,用户可以通过Anthropic的网页客户端和iOS应用免费试用新模型,Claude Pro和Claude Team的订阅用户将获得五倍的速率限制。此外,新模型也...……更多
2024-06-21 12:43:00劲敌,模型,智能,测试,模型,前代

...做基础技术,另一方面让AI能够越用越懂用户,可以基于上下文理解与学习用户的意图,基于位置、时间对消费者习惯进行整合式机器决策。比如2022年的MagicOS7.0,可基于地理围栏、用户习惯等信息主动提供建议引导及服务,例...……更多
2023-12-29 15:35:00荣耀,范式,人机,荣耀,人机,用户

...己的 GPT。根据官方说法,这一波 GPT 的升级包括:更长的上下文长度:128k,相当于 300 页文本。
更高的智能程度,更好的 JSON / 函数调用。
更高的速度:每分钟两倍 token。
知识更新:目前的截止日期为 2023 年 4 月。
定制化:GPT...……更多
2023-11-08 18:08:00模型,测试,用户,代码,基准,尝试

...成本效益成本效益是新Voyage-3系列模型的核心。Voyage-3的上下文长度为32000个tokens,是OpenAI产品的4倍,是需要高质量检索的企业的成本效益解决方案,且价格亲民。Voyage-3的成本为每百万个tokens0.06美元,比CohereEnglishV3便宜1.6倍,.……更多
2024-09-29 07:23:00嵌入式,模型,两个,模型,成本,维度

...幅提升。该模型基于超过 10TB tokens 训练,具备 200K 推理上下文窗口(相当于 36.5 万个汉字),推理时上下文窗口达到 200K 左右,提供自然语言处理、图片生成、自动化数据标注、自定义模型训练等多种大模型及能力。 ……更多
2024-06-25 09:43:00商汤,助手,重点,智能,办公,程序

...之后,Llama 3.1 终于在昨夜由官方正式发布了。Llama 3.1 将上下文长度扩展到了 128K,拥有 8B、70B 和 405B 三个版本,再次以一已之力抬高了大模型赛道的竞争标准。对 AI 社区来说,Llama 3.1 405B 最重要的意义是刷新了开源基础模型的...……更多
2024-07-25 09:32:00模型,论文,模型,训练,论文,开发

...”字,其实暗示了我大概率是承德户口。第三个,它结合上下文,把所有信息点组合在一起,准确理解了真正的问题,也就是“一名河北承德户籍的用户,能不能用北京的公积金在承德贷款购房”,然后针对这个问题给出了回答...……更多
2023-10-18 07:55:00人类,突破,李彦,文心,模型,公积

...是由字节的云雀大模型提供底层技术,支持最高30轮携带上下文轮数。除了能打造自己的AI Bot,Coze也对大众开放了GPT商店。用户在创建AI Bot的基础上,还可以将AI Bot公开给其他用户使用,同时也可以体验到其他用户或开发者开发...……更多
2024-02-04 20:05:00字节,机器人,商店,机器,字节,模型

...绝采样(RS)和直接偏好优化(DPO)。具体来说,Meta 将上下文窗口长度扩展到了 128K 个 token,同时保持与预训练模型相同的质量。为了提高模型的性能,Meta 也采用了生成合成数据的方法,他们筛选高质量的混合数据,来优化模...……更多
2024-09-27 13:42:00推理,可在,图像,运行,版本,支持

...的环境信息,从三维形状和空间位置、到视觉特征、再到上下文环境指令,为模型提供了一个综合的世界视图。从而能够理解并响应非精确或模糊的指令,显著提高具身智能系统的适应性和执行效率。图丨LPLM 算法模型架构(来...……更多
2024-03-22 10:31:00模态,语法,校友,模型,智能,智能

...发布了全新的Mistral-NeMoAI大语言模型,拥有120亿个参数,上下文窗口(AI模型一次能够处理的最大Token数量)为12.8万个token。VentureBeat与Midjourney合作制作Mistral-NeMoAI大模型主要面向企业环境,让企业不需要使用大量云资源的情况下..……更多
2024-07-19 22:18:00英伟,模型,语言,人工智能,模型,人工

...的安全风险。在大语言模型可信性评估常用的越狱攻击和上下文隐私泄漏任务中,如果提供给模型一张与文本无关的图片,原本的安全行为就可能被破坏(如图2)。
结果分析和关键结论图8 实时更新的可信度榜单(部分)研究...……更多
2024-07-25 09:31:00模态,清华,可信度,领衔,可信,几何

...真实标签。输出数据生成输出数据生成阶段采用了典型的上下文学习方法:研究者向模型提供任务指令和原始示例,使模型对输入生成阶段产生的每一个输入进行标注。在获取所有输出后,再进行一轮基于规则的过滤,以选择最...……更多
2024-08-02 09:40:00清华,性能,任务,数据,学习,生成

...不是基于检索的。当然,这个生成过程必须是智能的、与上下文相关的。我相信,未来人们电脑上的几乎每一个像素、每一次交互都将通过生成过程产生,我相信 Sam 也这么认为。希望通过 Blackwell 新一代架构能为生成式 AI 这个...……更多
2024-03-22 08:00:00差别,对话,英伟,芯片,模型,软件
更多关于科技的资讯:

第十四届中国创新创业大赛——首届具身智能专业赛成果在厦发布。厦门网讯(文/厦门日报记者 吴晓菁 通讯员 高菲 康潇潇 图/厦门日报记者 卢剑豪)昨日的厦门国际会议中心酒店
2025-09-26 08:38:00
具身智能孵化加速器在厦正式揭牌第十四届中国创新创业大赛首届具身智能专业赛昨日发布成果东南网9月26日讯(海峡导报记者 黄奕琳)昨日
2025-09-26 10:17:00

日前,2025年农业机械检测实验室间比对活动在山东潍坊举行。该活动由中国农业机械化协会主办、农机鉴定检测分会承办、潍柴雷沃智慧农业协助开展
2025-09-26 07:05:00

560余家企业携4.8万余个岗位来东大揽才“AI+”岗位热度不减,实战经验是核心指标□南京日报/紫金山新闻记者何洁 实习生黄佳琪杨久久9月25日
2025-09-26 07:41:00
9月24日,“青春华章・向西而歌”网络大思政课活动上,西安交通大学微电子学院集成电路工程专业博士研究生魏上杰介绍,集成电路是“国之重器”的“心脏”
2025-09-25 09:44:00

企查查APP显示,近日,杜建英持股的杭州芸台文化创意有限公司被吊销,原因是公司成立后无正当理由超过6个月未开业,或者开业后自行停业连续6个月以上
2025-09-25 11:20:00

9月25日,雷军发文:这5年,小米一路摸爬滚打、跌宕起伏,依然启动了造车、芯片和高端化……没什么好犹豫的,五十来岁,正是闯的年纪
2025-09-25 11:20:00

赤水河畔,国内首台高温复合型仿生压曲机稳定运转,物联网实时优化发酵参数……这场酿酒的“数字革命”,也是贵州习酒公司以全链数智革新推动产业跃迁的生动缩影
2025-09-25 11:57:00

在人工智能技术日臻成熟的2025年,AI已是深度融入职场生态的“数字同事”,在AI辅助下的2025年职场迎来了哪些变化
2025-09-25 13:30:00
国庆前夕,房山区物美超市“胖改店”、居然之家房山店、瑞莱广场分别于9月26日、27日、28日开业,进一步丰富了房山区消费场景
2025-09-25 13:38:00

企查查APP显示,近日,负责OPPO项目的杭州逗酷软件科技有限公司发生工商变更,新增山子高科旗下浙江山子超影科技有限公司为股东
2025-09-25 16:25:00