- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...。现阶段,视觉生成模型擅长创建逼真的视觉内容,然而从头开始训练这些模型的成本和工作量仍然很高。比如 Stable Diffusion 2.1 花费了 200000 个 A100 GPU 小时。即使研究者使用最先进的方法,也需要在 8×H100 GPU 上训练一个多月的...……更多
2024-07-30 09:37:00从头,模型,训练,参数,掩蔽,训练

...推进了一大步:论文地址:https://arxiv.org/abs/2407.15811——从头开始训练一个11.6亿参数的扩散模型,只需要1890美元!对比SOTA有了一个数量级的提升,让普通人也看到了能摸一摸预训练的希望。更重要的是,降低成本的技术并没有...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

只要改一行代码,就能让大模型训练效率提升至1.47倍。拥有得州大学奥斯汀分校背景四名华人学者,提出了大模型训练优化器Cautious Optimizers。在提速的同时,Cautious能够保证训练效果不出现损失,而且语言和视觉模型都适用。...……更多
2024-11-28 09:58:00训练,模型,团队,速度,代码,华人
...次开源的意义,有热心网友也帮忙总结了:对于任何想要从头开始训练模型或微调现有模型的人来说,数据管理过程是必须研究的。当然,除了OpenAI和苹果,上周Mistral AI联合英伟达也发布了一个12B参数小模型。
HuggingFace创始人...……更多
2024-07-23 09:33:00苹果,一口,模型,一口气,训练,过程

...重和网络架构。xAI 表示,开源版大模型Grok-1是一个由 xAI 从头开始训练的 3140 亿个参数混合专家模型。据介绍,基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调;3140 亿参数的 MoE 模型,在给定 token 上的激...……更多
2024-03-18 11:50:00马斯,马斯克,模型,全球,马斯,马斯克
...,一名工程师 Jay Mody 在一篇文章汇总将用 60 行 NumPy 代码从头实现一个 GPT。并把 GPT-2 模型权重加载到实现中,从而生成文本。原文链接:https://jaykmody.com/blog/gpt-from-scratch/作者 |Jay Mody译者| 禾木木出品 ……更多
2023-02-15 11:00:00从头,代码,技巧,模型,矩阵,输入

...且需要高度同步,一次错误就可能导致整个训练工作必须从头再来。报告显示,为期45天的预训练阶段中,总共出现了466次工作中断,其中47次是计划内的自动维护,419次是意外的,且大部分都来自硬件问题,GPU又是最多的,占...……更多
2024-07-29 11:30:00时报,模型,训练,参数,训练,错误
...基于已有模型通过upcycle(向上复用)开始训练,不然就从头开始训练。Upcycle方式所需算力相对更低、训练效率更高,但随随便便就到这种方式的天花板了。比如基于拷贝复制得到的MoE模型,非常容易出现专家同质化严重的情况...……更多
2024-11-22 09:54:00指令,模型,国产,全球,模型,模态

...size 的 scaling。Scaling model 是通常改变模型结构,往往需要从头训练整个模型,带来了过多的资源消耗,使其越来越不切实际。在本文中,研究团队使用 token 这一概念建模所有的计算,即将 model parameters 也视为一种 token,网络的...……更多
2024-11-15 09:51:00马普,北大,网络,模型,增量式,增量

...了整个模型的推理速度。为什么要把Llama变成Mamba?因为从头开始训练一个大模型太贵了。Mamba也火了这么长时间了,相关的研究每天都有,但自己训练大尺寸Mamba模型的却很少。目前比较有名的是AI21的Jamba(进化到了1.5版本,最...……更多
2024-09-06 10:01:00推理,更快,性能,模型,输出,训练

...业创新步伐基于腾讯混元的开源模型,开发者及企业无需从头训练,即可直接用于推理,并可基于腾讯混元系列打造专属应用及服务,能够节约大量人力及算力。同时,各大模型研发团队均可基于腾讯混元模型进行研究与创新,...……更多
2024-12-04 09:48:00文生,腾讯,模型,参数,社区,视频

...领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。目前虽然有不少基础模型已经提出,但如何有效地在高度多样化的时序数据上训练基础模型仍是一个开放问题。近期,来自...……更多
2024-11-01 09:27:00时序,下一代,视角,模型,基础,设计

...惜,GPT-3 至今也没有开源,未来也大概率不会开源了。要从头训这么一个 1750 亿参数的大型生成式语言模型,难度非常大。有人可能要说,那我们训一个小点的模型,比如百亿参数的,可行吗?目前来看不可行。 AI 的表现并非...……更多
2023-03-01 03:00:00模型,训练,达摩,参数,能力,集群

...界主流的个性化精品数字人通常属于在单个目标人数据上从头训练的小模型,虽然这种小模型能够有效地学到说话人的外表和说话风格,这种做法存在低训练效率、低样本效率、低鲁棒性的问题。相比之下,近年来许多工作专注...……更多
2024-11-01 09:27:00模型,高质量,训练,数字,个性,模型

...来的,其中稀疏记忆格式保持了真实的存储大小;研究者从头开始训练了一个具有 2.4B 非嵌入参数的 Memory3 模型,其性能超过了更大规模的 SOTA 模型。它还比 RAG 具有更好的性能和更快的推理速度;
此外,Memory3 提高了事实性并...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

...了优化。 2、自定义模型构建:允许用户根据自己的需求从头开始构建模型,提供灵活的模型架构设计工具。 3、训练环境配置:提供所需的计算资源,包括GPU、TPU等加速硬件,以及相应的软件环境。 4、超参数调优:帮助用户...……更多
2024-08-07 09:45:00模型,服务,平台,科技,模型,数据
...了自动提示词工程的概念、原理和工作流程,并通过代码从头实现了这一方法。自动提示词工程是什么?自动提示词工程(APE)是指自动生成和优化 LLM 提示词的技术,目标是提升模型在特定任务上的性能。其基于提示词工程的...……更多
2024-09-10 13:39:00从头,人工,提示,指南,工程,提示

...们想了解更多 OpenAI 的开放部分’。回到模型本身,Grok-1 从头开始训练,并且没有针对任何特定应用(如对话)进行微调。相对的,在 X(原 Twitter)上可用的 Grok 大模型是微调过的版本,其行为和原始权重版本并不相同。
Grok-1...……更多
2024-03-18 11:51:00马斯,马斯克,权重,架构,模型,参数

...k-1的参数是最多的。XAI官网的信息还显示,Grok-1是由他们从头开始训练的模型,此次发布的是预训练阶段结束时的原始基础模型检查点,预训练阶段在去年10月份完成。这也就意味着他们开源的模型,没有进行针对对话等任何具...……更多
2024-03-18 20:19:00马斯,马斯克,模型,是在,马斯,马斯克

...适配大模型预训练预训练是指,使用数万亿个token数据,从头开始训练LLM的过程,通常使用自监督算法进行训练。最常见的情况是,训练通过自回归预测下一个token(也称为因果语言建模)。预训练通常需要数千个GPU小时(105-107...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...到充分重视,尽管它直接影响了我们最寄予厚望的项目。从头开始重新训练模型,是一条艰难的道路LoRA如此有效的部分原因在于,与其他形式的微调一样,它是可堆叠的。可以应用指令调整改进模型,这样在其他贡献者添加对...……更多
2023-05-07 20:36:00惨败,狂潮,巨头,文件,模型,训练

...一个由xAI 2023年10月使用基于JAX和Rust的自定义训练堆栈、从头开始训练的3140亿参数的混合专家(MOE)模型,远超OpenAI的GPT模型。而此次开源的模型是是Grok-1预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微...……更多
2024-03-20 13:44:00马斯,马斯克,模型,全球,马斯,马斯克

...型都是在大语言模型LLM之上生长出多模态的应用,而并非从头开始训练的多模态的大模型,这是多模态大模型目前“不能言说的秘密”。
图源:中信建投证券谷歌自己也提到,到目前为止,创建多模态模型的标准方法基本是针...……更多
2023-12-07 10:31:00强悍,模型,模态,模型,训练,能力

...流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。近日,来自于香港科技大学(广州)、南方科技大学、...……更多
2024-11-23 09:42:00轨迹,模型,驱动,基础,全球,轨迹

...ear替换注意力(MHA)和前馈网络(FFN)中的线性投影,以从头开始学习1.58 bit权重。对于激活值,采用混合量化和稀疏化策略来减轻异常值维度引入的误差。图2说明了模型大小为7B的BitNet b1.58中,每个模块输入的分布。注意力层...……更多
2024-12-06 09:55:00架构,激活,新一代,模型,突破,激活
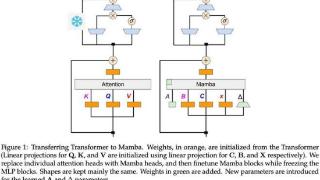
...在聊天基准测试和一般基准测试中优于使用数万亿 token 从头开始训练的开源混合 Mamba 模型。此外,该研究还提出了一种硬件感知推测解码算法,可以加快 Mamba 和混合模型的推理速度。
论文地址:https://arxiv.org/pdf/2408.15237该研...……更多
2024-09-03 09:59:00线性,新作,混合,作者,模型,线性

...都要先获得这个场景里的这些数据,根据你所用的模型,从头开始去训练,尽管之前模型不像现在的模型参数这么大,一亿个参数在去年可能还算是一个挺大的,今年大家都说10亿是小模型,其实也是很大规模的模型。图像、语...……更多
2023-12-21 14:31:00模型,升级,开放,服务,模型,应用

...识也就是,较小的模型可以借助教师模型的指导,获得比从头开始训练更好的性能。为此,Meta在预训练阶段融入了来自Llama 3.1 8B和70B模型的logits(模型输出的原始预测值),并将这些较大模型的输出则用作token级的目标。后训练...……更多
2024-09-27 13:39:00模态,宝宝,模型,图像,训练,文本
...亿稠密模型能够促进整个开源社区的发展,让大家不需要从头开始训练万亿参数模型,也就不需要从头解决收敛的问题。”具身智能得益于大模型的通用能力,机器人有了注入“灵魂”的可能。王仲远提到,智能体很可能会成为...……更多
2024-06-16 23:38:00背后,故事,模型,智能,技术,研究院

...壁。同时,专科的教育资源分散,每个小模型都需要分别从头进行基础训练,作为父母的人类,大多有着培养出全才的期望。2017年,谷歌发明了一种新的教育方式:Transformer模型。以往的“专科教育”中,AI的学习十分依赖人类...……更多
2023-03-15 16:33:00创业者,中国,模型,创业,模型,企业
更多关于科技的资讯:
本文转自:人民日报中国锦屏地下实验室——在极深地下探寻前沿领域(新春走基层·探访新质生产力)本报记者 王明峰 林 渊《人民日报》(2025年02月04日第 02 版)从四川西昌市驱车两个多小时
2025-02-04 05:45:00
效率提升20倍近日,记者走进杭州大雅信息科技有限公司(以下简称“大雅科技”),看到了一番忙碌的景象:设计师们正忙着出设计图
2025-02-04 08:00:00

快科技2月3日消息,就在今日,日本气象部门预报,该国多地4日起将遭遇今冬以来最强寒潮,部分地区恐出现“灾害级”强降雪。受强冷空气及冬季气压分布影响
2025-02-04 00:11:00
蛇年春节,我市消费市场一片红红火火,餐饮、文旅和影院作为传统的“三驾马车”依然强劲,而今年又有了生力军,在国补政策的加持下
2025-02-04 07:46:00

北京时间2月3日上午,OpenAI正式推出面向深度研究领域的智能体产品深度研究(Deep research)功能。 曾经一位经验丰富的行业分析师需要花费数天甚至数周才能完成的专业研究报告
2025-02-04 04:25:00

2月3日消息,消防通道是“生命通道”,在火灾等紧急情况下,它能为消防救援提供便利,确保人员迅速疏散和消防车辆快速到达现场
2025-02-03 23:41:00

快科技2月3日消息,近日有用户反映质疑华硕的PCIe Q-Release Slim快拆设计方案不完善、存在缺陷,有可能会损伤显卡的金手指
2025-02-03 23:41:00

快科技2月3日消息,微软时不时会在其官方网站上宣布停用某项Windows功能或服务,而这些被弃用的功能通常是使用率太低
2025-02-03 22:41:00

快科技2月3日消息,北京时间1月29日8点23分,印度使用GSLV-F15火箭成功发射了NVS-02区域导航卫星,而在4天后的2月2日16点30分
2025-02-03 17:40:00

快科技2月3日消息,《哪吒之魔童闹海》毫无意外拿下春节档票房冠军,影片爆火背后,是制作团队的用心。据悉,比起前作《哪吒之魔童闹海》整个故事更宏大
2025-02-03 18:10:00

快科技2月3日消息,对于国人来说,8、6都是吉利数字,连续出现更是吉利翻倍,今天就来看看超级吉祥、超级霸气的D8888次动车列车
2025-02-03 18:10:00

快科技2月3日消息,最新报道称,全球最大晶圆代工厂台积电正计划在中国台湾台南建设一座拥有最先进1nm工艺节点制程技术产线的晶圆厂
2025-02-03 18:10:00

快科技2月3日消息,今天百度智能云正式宣布DeepSeek-R1和DeepSeek-V3模型已在百度智能云千帆平台上架
2025-02-03 19:10:00

快科技2月3日消息,世界之大,无奇不有,近日,美国芝加哥Aldi超市发布公告称,超市冷藏柜中有只狼,当警方赶到现场后用工具将狼抓住
2025-02-03 19:40:00
快科技2月3日消息,今天阿里云宣布,阿里云PAI Model Gallery支持云上一键部署DeepSeek-V3、DeepSeek-R1
2025-02-03 19:40:00