- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...。现阶段,视觉生成模型擅长创建逼真的视觉内容,然而从头开始训练这些模型的成本和工作量仍然很高。比如 Stable Diffusion 2.1 花费了 200000 个 A100 GPU 小时。即使研究者使用最先进的方法,也需要在 8×H100 GPU 上训练一个多月的...……更多
2024-07-30 09:37:00从头,模型,训练,参数,掩蔽,训练

...推进了一大步:论文地址:https://arxiv.org/abs/2407.15811——从头开始训练一个11.6亿参数的扩散模型,只需要1890美元!对比SOTA有了一个数量级的提升,让普通人也看到了能摸一摸预训练的希望。更重要的是,降低成本的技术并没有...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练
...次开源的意义,有热心网友也帮忙总结了:对于任何想要从头开始训练模型或微调现有模型的人来说,数据管理过程是必须研究的。当然,除了OpenAI和苹果,上周Mistral AI联合英伟达也发布了一个12B参数小模型。
HuggingFace创始人...……更多
2024-07-23 09:33:00苹果,一口,模型,一口气,训练,过程

...重和网络架构。xAI 表示,开源版大模型Grok-1是一个由 xAI 从头开始训练的 3140 亿个参数混合专家模型。据介绍,基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调;3140 亿参数的 MoE 模型,在给定 token 上的激...……更多
2024-03-18 11:50:00马斯,马斯克,模型,全球,马斯,马斯克

...且需要高度同步,一次错误就可能导致整个训练工作必须从头再来。报告显示,为期45天的预训练阶段中,总共出现了466次工作中断,其中47次是计划内的自动维护,419次是意外的,且大部分都来自硬件问题,GPU又是最多的,占...……更多
2024-07-29 11:30:00时报,模型,训练,参数,训练,错误

...基于已有模型通过upcycle(向上复用)开始训练,不然就从头开始训练。Upcycle方式所需算力相对更低、训练效率更高,但随随便便就到这种方式的天花板了。比如基于拷贝复制得到的MoE模型,非常容易出现专家同质化严重的情况...……更多
2024-11-22 09:54:00指令,模型,国产,全球,模型,模态

...size 的 scaling。Scaling model 是通常改变模型结构,往往需要从头训练整个模型,带来了过多的资源消耗,使其越来越不切实际。在本文中,研究团队使用 token 这一概念建模所有的计算,即将 model parameters 也视为一种 token,网络的...……更多
2024-11-15 09:51:00马普,北大,网络,模型,增量式,增量

...了整个模型的推理速度。为什么要把Llama变成Mamba?因为从头开始训练一个大模型太贵了。Mamba也火了这么长时间了,相关的研究每天都有,但自己训练大尺寸Mamba模型的却很少。目前比较有名的是AI21的Jamba(进化到了1.5版本,最...……更多
2024-09-06 10:01:00推理,更快,性能,模型,输出,训练

...领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。目前虽然有不少基础模型已经提出,但如何有效地在高度多样化的时序数据上训练基础模型仍是一个开放问题。近期,来自...……更多
2024-11-01 09:27:00时序,下一代,视角,模型,基础,设计

...来的,其中稀疏记忆格式保持了真实的存储大小;研究者从头开始训练了一个具有 2.4B 非嵌入参数的 Memory3 模型,其性能超过了更大规模的 SOTA 模型。它还比 RAG 具有更好的性能和更快的推理速度;
此外,Memory3 提高了事实性并...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

...界主流的个性化精品数字人通常属于在单个目标人数据上从头训练的小模型,虽然这种小模型能够有效地学到说话人的外表和说话风格,这种做法存在低训练效率、低样本效率、低鲁棒性的问题。相比之下,近年来许多工作专注...……更多
2024-11-01 09:27:00模型,高质量,训练,数字,个性,模型

...了优化。 2、自定义模型构建:允许用户根据自己的需求从头开始构建模型,提供灵活的模型架构设计工具。 3、训练环境配置:提供所需的计算资源,包括GPU、TPU等加速硬件,以及相应的软件环境。 4、超参数调优:帮助用户...……更多
2024-08-07 09:45:00模型,服务,平台,科技,模型,数据
...了自动提示词工程的概念、原理和工作流程,并通过代码从头实现了这一方法。自动提示词工程是什么?自动提示词工程(APE)是指自动生成和优化 LLM 提示词的技术,目标是提升模型在特定任务上的性能。其基于提示词工程的...……更多
2024-09-10 13:39:00从头,人工,提示,指南,工程,提示

...们想了解更多 OpenAI 的开放部分’。回到模型本身,Grok-1 从头开始训练,并且没有针对任何特定应用(如对话)进行微调。相对的,在 X(原 Twitter)上可用的 Grok 大模型是微调过的版本,其行为和原始权重版本并不相同。
Grok-1...……更多
2024-03-18 11:51:00马斯,马斯克,权重,架构,模型,参数

...k-1的参数是最多的。XAI官网的信息还显示,Grok-1是由他们从头开始训练的模型,此次发布的是预训练阶段结束时的原始基础模型检查点,预训练阶段在去年10月份完成。这也就意味着他们开源的模型,没有进行针对对话等任何具...……更多
2024-03-18 20:19:00马斯,马斯克,模型,是在,马斯,马斯克

...适配大模型预训练预训练是指,使用数万亿个token数据,从头开始训练LLM的过程,通常使用自监督算法进行训练。最常见的情况是,训练通过自回归预测下一个token(也称为因果语言建模)。预训练通常需要数千个GPU小时(105-107...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...一个由xAI 2023年10月使用基于JAX和Rust的自定义训练堆栈、从头开始训练的3140亿参数的混合专家(MOE)模型,远超OpenAI的GPT模型。而此次开源的模型是是Grok-1预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微...……更多
2024-03-20 13:44:00马斯,马斯克,模型,全球,马斯,马斯克

...型都是在大语言模型LLM之上生长出多模态的应用,而并非从头开始训练的多模态的大模型,这是多模态大模型目前“不能言说的秘密”。
图源:中信建投证券谷歌自己也提到,到目前为止,创建多模态模型的标准方法基本是针...……更多
2023-12-07 10:31:00强悍,模型,模态,模型,训练,能力
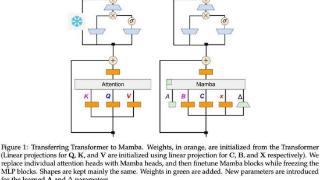
...在聊天基准测试和一般基准测试中优于使用数万亿 token 从头开始训练的开源混合 Mamba 模型。此外,该研究还提出了一种硬件感知推测解码算法,可以加快 Mamba 和混合模型的推理速度。
论文地址:https://arxiv.org/pdf/2408.15237该研...……更多
2024-09-03 09:59:00线性,新作,混合,作者,模型,线性

...都要先获得这个场景里的这些数据,根据你所用的模型,从头开始去训练,尽管之前模型不像现在的模型参数这么大,一亿个参数在去年可能还算是一个挺大的,今年大家都说10亿是小模型,其实也是很大规模的模型。图像、语...……更多
2023-12-21 14:31:00模型,升级,开放,服务,模型,应用

...识也就是,较小的模型可以借助教师模型的指导,获得比从头开始训练更好的性能。为此,Meta在预训练阶段融入了来自Llama 3.1 8B和70B模型的logits(模型输出的原始预测值),并将这些较大模型的输出则用作token级的目标。后训练...……更多
2024-09-27 13:39:00模态,宝宝,模型,图像,训练,文本
...亿稠密模型能够促进整个开源社区的发展,让大家不需要从头开始训练万亿参数模型,也就不需要从头解决收敛的问题。”具身智能得益于大模型的通用能力,机器人有了注入“灵魂”的可能。王仲远提到,智能体很可能会成为...……更多
2024-06-16 23:38:00背后,故事,模型,智能,技术,研究院

...Net b1.58将每个参数仅用三元值表示,但是所有这些都需要从头开始训练模型,并不是谁都有预算来进行LLM预训练。而Huggingface Transformers最近整合了BitNet b1.58,运用了一些技巧,使得现有模型可以直接微调到1.58bit。感兴趣的童鞋...……更多
2024-10-23 12:05:00模型,微软,推理,框架,参数,模型

...十亿个值,从而尽可能减少存储参数所需的空间。让我们从头开始,探索数值是如何表示的,然后再进行优化。如何表示数值数值存储的形式通常是浮点数(floting point number,或简称为floats):一个带有小数点的正数或负数。这...……更多
2024-08-01 09:38:00干货,可视化,模型,工程师,指南,工程
...中则提供了对话示例。
实验及评估在表6中可以发现,与从头开始训练相比,从更大的模型中提炼出来的结果提高了性能。需要注意的是,500B个token是2.6B模型最佳计算token数的10倍。研究团队从7B模型进行蒸馏,以保持与从27B模...……更多
2024-06-29 09:37:00诚意,经济,模型,训练,性能,注意力

快科技6月14日消息,摩尔线程与全学科教育AI大模型“师者AI”联合宣布,双方已完成大模型训练测试。师者AI基于摩尔线程夸娥(KUAE)千卡智算集群,完成了其70亿参数大模型的高强度训练测试。整个训练过程用时一周,训练...……更多
2024-06-14 11:37:00摩尔,师者,集群,线程,模型,训练

...于数据量有多大。最后,是你的数据标注成本。你如果要从头开始训一个70b的模型,用云的弹性资源可能需要3000万。如果要训参数量更大一点的模型,成本上亿都有可能的。这还是有经验的人去训,如果没经验,中间走了一些...……更多
2024-08-28 09:44:00业内人士,模型,业内,根本,人士,成本
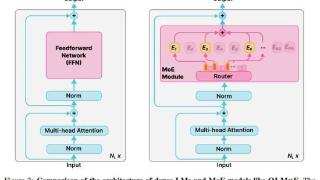
... checkpoint、训练日志和训练数据都已经开源。尽管大语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建...……更多
2024-09-06 10:01:00推理,模型,成本,参数,模型,训练

就在刚刚,Meta 发布了其最先进开源大型语言模型的下一代产品——Llama 3。据介绍,Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据,提供了 8B 和 70B 的预训练和指令微调版本,可以支持广泛的应用。同时,Llama 3 在广泛的行业...……更多
2024-04-20 11:03:00模型,训练,参数,数据,全球,模型

...城实验室主任高文发表演讲,分享了鹏城实验室在打造大模型平台上的进展。他表示,大模型训练首先需要一个平台。“现在要想训练一个大模型,需要有几千块卡,甚至上万块卡。”他介绍到,鹏城实验室在2020年就搭建了这...……更多
2024-06-05 13:00:00高文,院士,实验室,模型,训练,实验
更多关于科技的资讯:

近日,国民APP高德地图正式发布其全面AI化新版“高德地图2025”,成为全球首个基于地图的10亿级AI Native原生应用
2025-08-09 16:47:00

鲁网8月9日讯第35届青岛国际啤酒节在金沙滩啤酒城狂欢正酣,这里不只有泡沫四溢的酒杯与欢呼的人群,更藏着一座能打包带走的“快乐宝藏库”
2025-08-09 11:41:00

过去几年,四川小伙王星程每天坚持分享自己的剪辑日常。得益于剪映专业版的方便易上手,“半路出家”的他很快就摸索出一套剪辑窍门
2025-08-08 15:27:00
天津,这座古老而又现代的城市,多元文化在建筑中显现、沉淀、交融。近年来,天津着力讲好建筑承载的故事,不仅使老建筑“重获新生”,更展现了天津厚重的人文底蕴与独特的城市魅力。
2025-08-09 07:44:00

从航空航天到汽车动力,从风洞实验到无人机飞行测试,精确的流场测量和压力数据采集是确保产品设计和研发进度的重要保障。很多科研工作者在采购压力扫描阀和气动探针后
2025-08-08 15:27:00

一、餐饮行业的成本之痛,政策改变迫使餐饮商家做出调整截至2025年,餐饮行业人工成本高达32.7%,较疫情前上升了8%
2025-08-08 15:27:00

近日,TikTok Shop新市场捷报频传!日本站点开放仅一个月,首场大促便斩获“开门红”;与此同时,欧洲五国德法意西
2025-08-08 15:27:00

药店买药免排队、秒支付!近日,通联支付与当地邮政联合,为云南“为了你健康药房”上线“好老板”轻应用,助力连锁药店升级一站式智慧收银平台
2025-08-08 15:27:00
追求健康美食的你,是否渴望一种便捷烹饪方式?空气炸锅正是你的理想选择!它利用高速循环热风,无需大量油脂就能烹饪出酥脆可口的食物
2025-08-08 15:27:00

近日,格力高首次向媒体开放其位于上海的智能化生产基地,揭秘这家百年食品企业如何通过“本土化研发+智能智造”双轮驱动,实现从消费者需求洞察到产品快速落地的高效转化
2025-08-08 15:27:00

当前,海量生物数据的处理与分析能力已成为制约行业发展的关键瓶颈。近日,依托曙光超智融合技术建设的华东某全国产计算中心,与单细胞测序领域代表性企业墨卓生物达成战略合作
2025-08-08 15:27:00

2025年8月5日,中国知名电竞音频品牌赛德斯(SADES)在广东深圳正式签约“品牌强国·自主品牌优选工程”,成功入选该国家级项目成员单位
2025-08-08 15:27:00
餐饮行业在服务消费中地位举足轻重。当下的中国餐饮行业正在经历从“速度增长”到“效率竞争”的结构性转变。根据中国烹饪协会发布的《2024年全国餐饮业发展回顾与2025年展望》(以下简称“报告”)数据显示
2025-08-08 15:27:00

名众集团自2018年自主研发首创了“四维形气美学”“草本0创还原术”后,历经7年研发60万例临床,再次实现重大技术突破
2025-08-08 15:27:00

会议室的桌面上总缠着一堆线缆 ——VGA 线、DP 线、HDMI 线像乱麻一样,某企业高管曾因笔记本找不到匹配接口,让二十多位参会者等了十来分钟
2025-08-08 15:32:00