- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...云DeepSeek大模型一体机,通过自研的算力池化能力、智能推理加速引擎,充分融合软硬件,实现了性能的全面提升,推理速度提升50%,企业可以根据自己的需求灵活选择不同版本,开箱即用。目前,在河南鹤壁、江苏宿迁、山东...……更多
2025-02-27 14:14:00京东,模型,领先,产品,企业,京东

...的Kimi国产大模型正式发布k0-math。k0-math是Kimi推出的首款推理能力强化模型,采用全新强化学习和思维链推理技术,通过模拟人脑的思考和反思过程,大幅提升解决数学难题的能力。据了解,在多项数学基准能力测试中,k0-math的...……更多
2024-11-18 08:22:00推理,新一代,模型,高考,模型,基准

...等工具如何为部署模型提供支持,助力大模型更加高效地推理。赵一嘉首先分享了 Stable Diffusion 背后模型的原理详解,细致地阐述了 Clip、VAE 和 Unet 等关键组件的工作原理。随着 Sora 爆火,也带火了背后的 DiT(扩散 Transformer)...……更多
2024-08-13 09:39:00文生,出图,美感,秘籍,心意,更快

...。人工智能时代,编程已成为未来世界的通用语言、培养下一代创新者的关键工具。作为点猫科技旗下人工智能和编程教育品牌,编程猫面向全球青少年提供覆盖全年龄段和多种编程语言的线上课程、线下学习、赛事等考等服务...……更多
2025-04-29 16:22:00商汤,编程,战略,合作,教育,科技

DeepSeek和o1/o3一类推理大模型持续带来震撼之际,有人开始研究他们的弱点了。最新研究揭示:在遇到高难度问题时,推理大模型可能像“三心二意的学生”一样频繁切换解题思路,却因缺乏深入探索而失败——这种现象被研究...……更多
2025-02-04 19:41:00弱点,模型,推理,答案,思路,准确率

...交视觉-语言-动作建模框架RevThink:使用逆向思维增强 LLM 推理想要第一时间获取每日最新大模型热门论文? 点击阅读原文,查看「2024必读大模型论文」合集,以及申请加入「大模型技术分享群」。SwiftEdit:50 倍速文本引导图像...……更多
2024-12-10 09:53:00模型,语言基础,清华,定律,密度,团队

...TadaoNagasaki)指出,尽管GPT-3与GPT-4的性能相差不大,但是下一代模型GPTNext预计将实现质的飞跃,其性能预计将提升100倍。 ……更多
2024-10-26 20:33:00人工智能,人工,模型,智能,模型,人工智能

...况下,用强化学习实现了性能上的跨越。此外,阿里还在推理模型中集成了与Agent相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。QwQ-32B 在一系列基准测试中进行了评估,测试了数学推...……更多
2025-03-06 07:42:00阿里,推理,模型,参数,全新,能力
文 | 周鑫雨编辑 | 邓咏仪36氪获悉,AI推理部署解决方案厂商“清昴智能”近日完成了数千万元Pre-A+轮融资,启赋资本、达晨财智领投,老股东奇绩创坛跟投。此前,清昴智能已获得某世界500强科技巨头公司的千万元战略投资。...……更多
2024-06-03 15:23:00数千,融资,芯片,模型,国产,智能

...历新一轮技术范式的变化,预训练 Scaling Law 放缓之后,推理时间计算成为了新的性能提升关键。两个月前,OpenAI o1 的诞生再次引领了大模型技术的突破。从后训练阶段入手,通过更多的强化学习、原生的思维链和更长的推理时...……更多
2024-11-19 09:50:00模型,国产,模型,推理,能力,数学

新智元报道编辑:乔杨【新智元导读】LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种...……更多
2024-08-08 16:23:00模态,领衔,基准,推理,视觉,能力

...Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。先来看一张其乐融融的图片(一眼AI):右边的小羊驼代表Llama,而左边的蛇(Mamba)也是我们的老熟人了。至于到底能不能其乐融融,咱就不管了,之所以有此场景...……更多
2024-09-06 10:01:00推理,更快,性能,模型,输出,训练

...于DeepSeek、Grok、OpenAl等冲击,AI正在从感知和生成式AI向推理和逻辑推理领域发展。而推理AI又增加了一条扩展规律——增加训练的计算能力能让模型变得更智能,而增加深度思考的计算能力则能让答案更精准,与一次性推理相比...……更多
2025-02-27 11:55:00英伟,推理,需求,英伟,增长,推理

微软开源1bit大模型推理框架!现在1000亿参数大模型量化后单CPU可跑,速度可达每秒5-7个token。就是今年爆火论文The Era of 1-bit LLMs的官方代码实现,开源不到一周GitHub已揽获7.9k Star。传统大模型参数以16位浮点数(如FP16或BF16)形...……更多
2024-10-23 12:05:00模型,微软,推理,框架,参数,模型
...算效率和算力开销两大问题成为新的行业焦点。对大模型推理成本的优化,可通过很多技术手段实现。首先是模型本身,模型结构、训练方法都可以持续改进,包括业界很关注的MoE(混合专家模型),就是优化推理成本很好的解决...……更多
2024-06-03 14:07:00模型,效率,成本,模型,推理,成本

...于算力领域,并致力于智能计算基础设施、大模型的训练推理算法以及工程优化的研究和开发。#中兴通讯绿色算力主力军#在算力领域,大模型的技术和应用已经成为一个趋势。大模型是一种基于深度学习技术的自然语言处理模...……更多
2023-12-04 10:08:00中兴通讯,推理,基础设施,模型,设施,训练

...天的新品发布会上,科大讯飞正式发布了具备深度思考和推理能力的星火深度推理模型X1,这也是目前唯一一个全国产算力上训练的深度推理模型。据介绍,与通用大模型相比,X1的解题过程更接近人类的“慢思考”方式,并且...……更多
2025-01-15 10:24:00讯飞,星火,推理,深度,模型,指标

谷歌发布全新反向推理算法LAMBADA,无惧搜索空间爆炸!自动推理绝对算是自然语言处理领域的一大难题,模型需要根据给定的前提和知识推导出有效且正确的结论。尽管近年来NLP领域借着大规模预训练语言模型在各种「自然语...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标

...特曼用一个简单的柱状图给出了对比:可以看到o1在数学推理和编程领域的表现要明显优于o1-preview,提升幅度在50%左右,而在科研领域的测试里,o1相对于o1-preview的表现就提升有限了。图源:OpenAI考虑到o1模型不需要额外加钱就...……更多
2024-12-11 20:12:00实测,国产,模型,推理,文心,答案

...各行各业的智能化转型,探讨如何设计、推动和重新定义下一代人工智能设备、基础设施、解决方案和服务,以加速为企业和消费者带来真正的人工智能驱动成果。联想Tech World 2023推出AI PC,明年9月上市,定位高端市场人工智能...……更多
2023-10-25 20:43:00合作,人工智能,智能,人工,联想集团,杨元庆
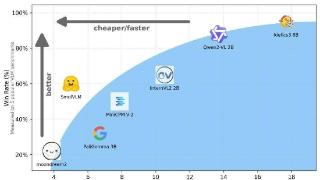
...lVLM AI 视觉语言模型(VLM),仅有 20 亿参数,用于设备端推理,凭借其极低的内存占用在同类模型中脱颖而出。官方表示 SmolVLM AI 模型的优点在于体积小、速度快、内存高效,并且完全开源,所有模型检查点、VLM 数据集、训练...……更多
2024-11-28 09:47:00推理,模型,参数,模型,吞吐量,吞吐

...换机芯片来搭建集群,后期也会考虑与合作伙伴共同研发下一代大规模交换机,持续发展卡间通信。
在框架和算法层面,夸娥万卡集群支持多种自适应混合并行策略与高效显存优化,可根据应用负载选择并自动配置最优的并行...……更多
2024-07-09 09:47:00摩尔,张建中,万卡,张建,集群,线程
...“小驰”的“聊天”将更加天马行空。“DeepSeek擅长逻辑推理,我们的DFM-2大模型具备跨多个专业垂直领域的综合大模型集合能力,能够学习和利用DeepSeek的逻辑推理能力,并基于在各个垂直领域的应用经验,多维度提升DFM大模型...……更多
2025-02-14 13:01:00新浪潮,新浪,百业,模型,苏州,模型

...级带来的性能提升却相当显著,特别是在前端开发、数学推理和上下文理解方面有了明显进步。据了解,新版V3模型借鉴DeepSeek-R1模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在数学、代码类...……更多
2025-03-25 23:03:00前端,推理,能力,版本,升级,开发

...到,人类大脑生成和解析语言的神经网络并不负责形式化推理,而且提出推理并不需要语言作为媒介。这篇论文声称「语言主要是用于交流的工具,而不是思考的工具,对于任何经过测试的思维形式都不是必需的」,引发了科技...……更多
2024-06-25 09:45:00推理,模型,思维,语言,社区,语言

...。Intel还采用KV Caching、PagedAttention机制和张量并行,提高推理效率。Intel的硬件也可利用软件框架和工具包进行加速,并获得出色的大模型推理性能,包括PyTorch以及Intel PyTorch扩展包、OpenVINO工具包、DeepSpeed、Hugging F……更多
2024-07-18 14:57:00三条,通义,阿里,模型,参数,通义
...基座大模型基础上,仅耗费数十美元就开发出相对成熟的推理模型。尽管其整体性能尚无法比肩美国开放人工智能研究中心(OpenAI)开发的o1、中国深度求索公司的DeepSeek-R1等,但此类尝试意味着企业可以较低成本研发出适合自...……更多
2025-02-27 05:08:00范式,模型,科研,团队,成本,全球
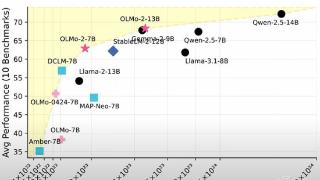
...前AI行业快速发展,竞争也越来越激烈,特别是各种高级推理模型之间的竞争。过去一段时间,中国科技公司陆续发布了3款自研的AI模型,分别是DeepSeek(深度求索)的Deepseek R1、阿里巴巴的Marco-1以及香港中文大学与商汤科技的...……更多
2024-12-04 09:48:00大佬,科技界,美国,模型,两个,小时
本文转自:人民网-安徽频道4月20日,科大讯飞深度推理大模型——讯飞星火X1迎来全新升级。作为当前业界唯一基于全国产算力训练的深度推理大模型,升级后的星火X1在数学、代码、逻辑推理、文本生成、语言理解、知识问答...……更多
2025-04-22 16:50:00讯飞,星火,行业应用,司法,升级,医疗

... 不仅将模型参数量由原版的671B提升至685B,编程、数学等推理思考能力大幅提升,性能表现可以与Claude3.5/3.7Sonnet相媲美。同时,模型的开源协议升级为更宽松的MIT许可,进一步降低了商业应用门槛。 优刻得云平台始终密切关注A...……更多
2025-03-25 18:45:00模型,平台,模型,推理,体验,可通
更多关于社会的资讯:
近日,商务部、中国人民银行、金融监管总局联合印发《关于加强商务和金融协同更大力度提振消费的通知》。《通知》提出3方面11条政策措施
2025-12-14 23:39:00
中国乒乓球协会14日发布声明,对国乒队员孙颖莎、王楚钦在世界乒乓球职业大联盟(WTT)香港总决赛期间因身体不适退赛作出回应
2025-12-15 04:20:00
12月13日,千万粉丝博主张凯毅在社交平台发的一个视频引发热议。视频中她称,丈夫在结婚时为她亲手打造的4斤重黄金凤冠,在自己办的免费展览上被人为破坏了
2025-12-14 08:05:00
商报讯 为加强对商业办公等非住宅类项目管道燃气的管理,提升燃气用户安全用气水平,杭州出台《市商业办公等非住宅类项目管道燃气管理办法》
2025-12-14 08:36:00
日前,杭州举行“礼让二十载 文明再升级”——城市礼让文化20周年主题活动,回顾、传承、深化这份跨越廿载的文明实践。活动现场
2025-12-14 08:36:00
当我们清晨被手机推送唤醒,指尖划过屏幕下单一份热腾腾的早餐;当我们依赖实时路径规划出行,穿行于城市脉络之间;当我们运动健身
2025-12-14 11:09:00
12月13日,著名演员何晴家属发布讣告显示,何晴在北京安然离世,享年61岁。告别仪式将于2025年12月15日早10点在北京昌平殡仪馆久安厅举行
2025-12-14 11:39:00
央视新闻客户端讯 记者从中国海油获悉,我国首个深水油田——流花油田二次开发项目全面投产,日产原油攀升至3900吨,创下产能新纪录
2025-12-14 11:39:00

这两天的杭州,着实有些寒冷,温度和之前相比,下降了非常多。本周末,浙江省表(导)演类服装表演专业统考在浙江理工大学临平校区举行
2025-12-14 11:40:00
不知道你有没有过这样的经历?拨打客服热线或点开一个网站的客服功能,出现的总是一位“AI客服”。对话时,“AI客服”听不懂话
2025-12-14 11:40:00
山东气温已降至冰点时间临近下班山东潍坊青州的徐先生突然感到有点饿了想到办公室放有红薯又有烤盆就开始用炭火烤红薯吃没想到因为门窗关得严实炭火不充分燃烧产生一氧化碳不知不觉间徐先生躺在沙发上昏了过去这时
2025-12-14 11:40:00
由中央网信办主办,以“奋斗的你我 奋进的中国”为主题的2025中国正能量网络精品征集展播活动正式启动。活动旨在征集遴选展播一批2025年1月1日至12月31日期间涌现的有内涵
2025-12-14 12:30:00

在酒香飘溢的中国酒都宿迁,洋河大曲的绵柔醇厚早已享誉全国,而近年来异军突起的宿迁市紫雨酿酒有限公司,正以“香、鲜、浓、醇
2025-12-14 15:19:00

2025年12月12日,瑞雪呈祥,由山东贯月科创集团主办的“创新创业·共创未来——贯月产业园区高质量发展新春书画联谊会”成功举办
2025-12-14 15:33:00