- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...自动化许多重复性的任务。例如,AI 可以自动处理图片、音频和视频等媒体文件,或者自动生成 HTML 和 CSS 代码。这些自动化工具可以大大提高开发效率和减少错误。其次,AI 还可以根据用户需求自动调整设计和功能。例如,当...……更多
2023-05-11 23:00:00前端,开发,开发,人工智能,前端,开发者

...的日渐成熟,以自动化、智能化的方式,将文本、图像、音频、视频等多模态数据重新组合,创造全新和从未有过的内容,在降低成本的同时,也打破了各个模态之间的“技术壁垒”,这就是视频AI的优势所在。11月8日,36氪WISE2...……更多
2023-11-17 14:49:00含量,大会,模型,文心,应用,商业

...GPT-4o具有强大的实时多模态交互性能:它可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出。这意味着,GPT-4o可以直接理解、直接生成音频或者视频一切内容,而无需通过文字的转译...……更多
2024-05-24 09:24:00网恋,用户,嘉丽,模型,人们,萨曼

...强大的无损压缩器视觉信息是知识的富矿:从文本走向多模态大数据时代的数据荒:运用合成数据破局AGI对人类社会经济活动影响:展望与思考写在前面:熵简科技是一家专注于帮助资管机构实现投研数字化的科技公司,主要客...……更多
2023-04-09 18:20:00压缩器,重磅,本质,数据,模型,人类

...型;4000亿参数、全球最大规模的开源MOE大模型。首先谈音频模型。据美国风投机构a16z上月发布的生成式AI产品Top 100报告,ChatGPT、Gemini等通用内容生产应用仍占据消费级AI应用大头。与6个月前的排名相比,有两个新类别首次进入...……更多
2024-04-19 16:00:00模型,国产,参数,媒体,天工,模型

...事”,Meta 开源 ImageBind 新模型,超越 GPT-4,对齐文本、音频等 6 种模态! 返回搜狐,查看更多责任编辑: ……更多
2023-05-11 13:00:00开放,能力,智能,模型,用户,搜索

...山大学、联想的研究团队推出了ConsistentID,可在细粒度多模态面部提示下,仅利用单张参考图像生成多样的肖像,且保持五官的一致性。
最终在人脸个性化任务处理上,相比腾讯的photomaker和小红书的instantID,在五官一致性保持...……更多
2024-05-22 15:47:00小兰,中山大学,人脸,中山,成果,个性
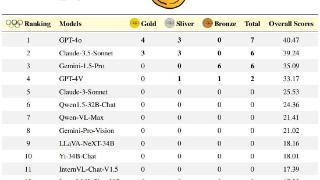
...数据泄露,从而反映模型的真实性能。研究团队测试了多模态大模型(LMMs)和纯文本大模型(LLMs)。对于LLMs的测试,输入时不提供任何与图像相关的信息给模型,仅提供文本。所有评估均采用零样本(zero-shot)思维链(Chain of ...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...体验。近期,标贝科技借助自研的语音合成测评系统,从音频音色的真实度、发音准确率、副语言表达三个维度,对几款主流GPT语音助手进行了全面的测评,深入了解当前GPT语音助手的合成音色质量,给用户提供更多的选择依据...……更多
2024-01-10 17:00:00音大,语音,助手,模型,体验,科技
...奇琦:从ChatGPT到Sora,是一个从单一文本到文本、图片、音频、视频多模态进阶的过程。虽然形态上有区别,但其本质都是通用人工智能拼图中的一部分,是实现通用人工智能前的一些小目标,具有内在连贯性。OpenAI接下来可能...……更多
2024-02-24 05:41:00狂飙,共识,规则,技术,人工智能,人工

...智能模型ImageBind,该模型能够将多种数据流,包括文本、音频、视觉数据、温度和运动读数等整合在一起。该模型目前只是一个研究项目,还没有直接的消费者或实际应用,但它展示了未来生成式人工智能系统的可能性,这些系...……更多
2023-05-10 10:23:00人工智能,感官,人工,模型,文本,音频

...,融合了当前最先进的语音预训练方法,并依托海量优选音频数据打造而成。该模型不仅支持普通话、英语及多种方言,还以其卓越的性能表现和极低的推理时延脱颖而出,广泛应用于快手的多种场景。理解了外部世界之后,受...……更多
2024-07-11 14:20:00快手,模型,答案,快手,模型,小芳

...。依托序列猴子大模型,「魔音工坊」可通过3-10秒的短音频,快速地实现声音克隆,并支持跨语言迁移、情感语气生成。其海外版DupDub还支持多语音音频生成,目前已涵盖英语、法语、日语、西班牙语、葡萄牙语、泰语等。
声...……更多
2024-07-07 18:45:00人工智能,浪潮,审美,人工,大会,智能

...数工作都集中在单一数据模态上,如视觉,语言,图,或音频等。这种单模态的关注忽略了现实世界环境的多模态本质,因为现实世界环境本身就很复杂,由不同的数据模态而不是单一模态组成。
随着多模态数据的快速增长,...……更多
2024-11-14 09:46:00模态,清华,中文,联合,学习,模态

...味着谷歌Pixel 9系列不仅可以理解文本,还能理解图像、音频和语音。其它参数方面,谷歌Pixel 9前置1050像素,后置5000万主摄和4800万超广角,电池是4700毫安时,支持45W快充。值得注意的是,谷歌Pixel 9出厂预装Android 14,并非Android...……更多
2024-08-14 09:37:00元起,旗舰,模态,支持,处理器,售价

...懂图片的内涵。在自然语言处理(NLP)中,文本、图像和音频信息都可以共同帮助理解和生成更丰富的内容。同样,在计算机视觉任务中,文本和图像信息“齐发”可以提高目标检测和场景理解的准确性。“具备多模态的生成能...……更多
2023-03-16 09:00:00就是,模型,阿拉贡,能力,训练,模态

...版本,首次上新音视频处理能力——最长可处理11小时的音频,或者1小时的视频。 OpenAl则又一次“狙击”谷歌,紧接着发布非预览版的GPT-4 Turbo,将之前独立的 GPT-4 Vision直接集成到模型中,只需一次API调用,该模型就可以分析...……更多
2024-04-14 20:33:00模型,特斯,马斯,芯片,融资,英特

...超拟人的语音合成效果。其首批40个语种平均MOS分(评估音频或视频质量的一种标准,5分为最高)提升了0.25,拟人测试中MOS达到4.5分,拟人度达到83%,拟人语音合成能力超越ChatGPT。星火语音大模型开源方向上,此次科大讯飞发...……更多
2024-01-31 07:32:00讯飞,拟人,语音,模型,能力,升级

...态大模型,该模型通过整合跨模态信息,能够接收文本、音频、图像等多种形式的输入,并实时生成文本、音频和图像的任意组合输出,带来了实时多模态拟人交互体验,开启了通用人工智能(AGI)的新范式。目前,在通用能力...……更多
2024-12-13 16:22:00甲子,潜力,模型,商业,模型,山海

...学自动提炼规律、小样本学习、代码项目级理解能力、多模态指令跟随与细节表达等能力,进一步提升星火的落地应用能力。升级AI人设、启发式对话,打造每个人的AI助手自讯飞星火9月5日全民开放后,当前已有1200万用户,也...……更多
2023-10-24 15:02:00讯飞,星火,助手,讯飞,星火,模型

...规模高达2100亿,覆盖蛋白质、DNA、RNA、细胞等七大主流模态。背后玩家正是来自李彦宏孵化创办的百图生科。与应用于其他行业的基础模型有所不同,他们解码的是生命语言,而非自然语言,意味着不仅能处理复杂的生物序列...……更多
2024-11-07 09:50:00模型,重构,生命科学,序列,生命,基础

...低。当地时间3月14日,ChatGPT开发商Open AI公开发布大型多模态模型GPT-4,与ChatGPT所用的模型相比,GPT-4“给它看张草图,一秒生成网站”的惊人表现被称为“王炸”产品。GPT-4发布后,A股市场的ChatGPT概念股并没有延续数月前的疯...……更多
2023-03-16 08:10:00何影,概念股,壁垒,视觉,概念,产业

...科技正式发布为眼镜等未来终端定向优化等自研WAKE-AI多模态大模型,具备文本生成、语言理解、图像识别及视频生成等多模态交互能力。 该大模型围绕GPS轨迹+视觉+语音打造新一代LLM-Based的自然交互,同时多模态问答技术的加...……更多
2024-04-19 14:30:00模态,模型,科技,模态,模型,场景
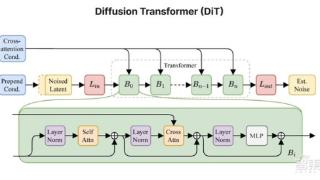
...节。Stable Audio Open是StabilityAI于今年6月推出的开源文本转音频模型,可免费生成长达47秒的样本和音效,还可生成44.1kHz高质量立体声音频,并且能在消费级GPU上运行。除了免费、开源,该模型还注重保护创作者版权,在数据训练...……更多
2024-07-25 09:22:00最新技术,火爆,模型,细节,音频,全球

...域产生深远影响;3)AI视频应用在算力消耗上远超文本、音频及图像,建议关注推理端算力需求提升,以及后续其商业化程度是否能形成收入和投资的正反馈。华鑫证券认为,Sora的推出有望推高AI多模态的热度,可关注AI多模态...……更多
2024-02-19 10:48:00大规,新高,票房,大规模,情报,机构
...还需要哪些技术支持?司马华鹏称:“我们的大模型是多模态的,是文本生成、声音生成和数字人生成的结合。其实很多人在反馈,他(刘强东)声音和节奏感与他原来讲话不太一样。这很可能克隆的是平时的语速,但是直播(...……更多
2024-04-21 22:43:00真人,直播,技术支持,数字,支持,时代

...后,在格式、质量等方面符合相关要求,以文本、图像、音频、视频等多模态呈现,可直接用于开发和训练人工智能模型的数据集,包含行业通识和行业专识数据集。四川省首批人工智能高质量数据集充分利用全省海量数据资源...……更多
2024-09-25 10:44:00四川省,人工智能,四川,高质量,人工,智能

...型调出来后,Star X在东南亚与中东核心国家排到了音乐和音频下载榜前三。接着它拿下了拉美和俄罗斯市场,今年的重点是欧洲。2021 年上半年,Star X 用户日平均在线时长为 49 分钟,仅次于 YouTube(77 分钟)、Tiktok(71 分钟)和...……更多
2022-12-19 09:02万维,昆仑,加速度,全球化,全球

...人员于在 2023 年 10 月低调发布的一个名为 Ferret 的开源多模态大模型也没有收到太多关注。当时,该版本包含代码和权重,但仅供研究使用,而非商业许可。但随着 Mistral 开源模型备受关注、谷歌 Gemini 即将应用于 Pixel Pro 和 Andr...……更多
2023-12-26 14:06:00模型,生态,模态,零碎,苹果,模型

...究团队及其合作者旨在为足球视频理解开发一个全面的多模态框架。具体来说,他们做出了以下贡献:(1)他们提出了 SoccerReplay-1988,这是迄今为止最大的多模态足球数据集,其中包括来自 1988 场完整比赛的视频和详细注释,...……更多
2024-12-10 09:53:00模型,语言基础,清华,定律,密度,团队
更多关于科技的资讯:

快科技2月27日消息,小米汽车发文称,很多小米SU7 Ultra准车主,都非常期待碳纤维双风道前舱盖。他们说,无他,就是觉得非常帅气
2025-02-27 07:35:00

昨日,位于江北新区的南京洛普科技有限公司车间内,工人正在装配、测试LED面板,赶制订单。该企业是国内率先研制、生产大型LED显示屏的企业
2025-02-27 08:04:00

快科技2月27日消息,近日,特斯拉FSD自动驾驶系统正式在国内开启测试,虽然是需要6.4万元选装,但还是有一些头部汽车博主第一时间进行了测试
2025-02-27 08:05:00
百位AI创想者齐聚杭州城西科创大走廊送出“七个一”专享政策礼包 最高将资助1亿元杭州日报讯 昨天,由中央广播电视总台联合杭州市人民政府主办的《赢在AI+》首届未来营
2025-02-27 08:14:00

快科技2月27日消息,大家知道吗?普速列车到终点站后,车头与车厢是分开走的。今天中国铁路官方进行了科普,原来,普速列车的车头和车厢隶属于不同的管理单位
2025-02-27 08:35:00

很多人都在网上刷到过采耳视频:在可视化镜头下,一块块陈年污垢被掏出来,要多解压有多解压。还有许多博主会前往采耳机构探店
2025-02-27 08:35:00

快科技2月27日消息,据媒体报道,从2月起,欧盟消费者开始在日常饮食中发现一种新食材:黄粉虫(Tenebrio molitor)幼虫粉末
2025-02-27 08:35:00

快科技2月27日消息,据报道,英伟达今日公布了该公司的2025财年第四财季及全年财报。财报显示,第四财季营收达到393
2025-02-27 08:35:00

2025年,以旧换新政策进一步加大力度,消费市场呈现繁荣景象。据商务部统计,春节期间,全国以旧换新实现销售860万台商品
2025-02-27 08:44:00
厦门网讯(厦门日报记者 楚燕 通讯员 陈雯 罗超)在电脑上打开医院电子病历系统,在任务栏点击DeepSeek,屏幕右侧立马出现智能问答对话框
2025-02-27 08:51:00

快科技2月27日消息,依然有很多人在执着于高考,而且非北大清华不上,对此你怎么看?“35岁再考清华”当事人李龙晒视频称2025高考100天倒计时
2025-02-27 09:05:00

消息人士称,Valve计划年内发布一款价位1200美元(接近一万元人民币)的VR头显,内部代号“Deckard”。其定价之高仅次于AVP与Meta Quest Pro
2025-02-27 09:05:00

快科技2月27日消息,浩鑫推出新一代准系统XPC nano NA10H7,整体尺寸为132 x 143 x 55 mm
2025-02-27 09:05:00

快科技2月27日消息,备受业界瞩目的英伟达业绩出来了,结果出奇的好,远远超出市场的预期。在2025财年,英伟达总共实现1304
2025-02-27 09:35:00