- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」Yann LeCun 也对他们的...……更多
2024-10-15 09:57:00模型,训练,方法,模型,训练,视觉

...Yann LeCun 批评 LLM 的推文之一相反,他更注重所谓的世界模型(World Model),也就是根据世界数据拟合的一个动态模型。比如驴,正是有了这样的世界模型,它们才能找到更省力的负重登山方法。近日,LeCun 团队发布了他们在世界...……更多
2024-11-19 09:48:00样本,模型,特征,视觉,训练,规划

...分认识并认可了表征学习的重要性,那么视觉领域的生成模型呢?最近,谢赛宁团队发表的一篇研究就拿出了非常有力的证据:Representation matters!扩散模型如何突破瓶颈? 成本高又难训练的DiT/SiT模型如何提升效率?对于这个问...……更多
2024-10-23 09:55:00新作,速度,训练,学习,模型,训练

...况,这一举动引起了业界的广泛关注。然而,在视觉语言模型的角逐中,谷歌也不甘示弱。
近日,Google Research、Google DeepMind 和 Google Cloud 共同推出了一个更小、更快、更强大的视觉语言模型(VLM)——PaLI-3,该模型与相似的体...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型
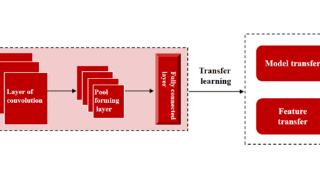
...景理解、图像分析、机器人感知和图像分割等。语义分割模型是计算机视觉领域中的一种模型,旨在将图像中的每个像素分配给特定的语义类别。与传统的图像分类模型只能给整个图像分配一个类别不同,语义分割模型能够为图...……更多
2023-11-15 01:02:00语义,全息,高质量,模型,任务,学习

...个使用扩散强迫(Diffusion-forcing)框架的无限时长电影生成模型,其通过结合多模态大语言模型(MLLM)、多阶段预训练(Multi-stage Pretraining)、强化学习(Reinforcement Learning)和扩散强迫(Diffusion-forcing)框架来……更多
2025-04-21 13:53:00万维,昆仑,团队,生成,视频,模型

...只用1890美元、3700 万张图像,就能训练一个还不错的扩散模型。现阶段,视觉生成模型擅长创建逼真的视觉内容,然而从头开始训练这些模型的成本和工作量仍然很高。比如 Stable Diffusion 2.1 花费了 200000 个 A100 GPU 小时。即使研...……更多
2024-07-30 09:37:00从头,模型,训练,参数,掩蔽,训练

今日值得关注的大模型前沿论文北大团队提出「自定义漫画生成」框架UniReal:通过学习真实世界动态实现通用图像生成和编辑苹果团队提出「可扩展视频生成」方法利用扩散 Transformer 进行视频运动迁移ObjCtrl-2.5D:无需训练的「...……更多
2024-12-13 09:19:00推理,模型,思维,空间,模型,生成

现在,长上下文视觉语言模型(VLM)有了新的全栈解决方案 ——LongVILA,它集系统、模型训练与数据集开发于一体。现阶段,将模型的多模态理解与长上下文能力相结合是非常重要的,支持更多模态的基础模型可以接受更灵活...……更多
2024-08-22 09:51:00英伟,准确率,支持,视频,序列,训练

...oogle 的 AI 研究实验室Google DeepMind 发布了一项关于训练 AI 模型的新研究,Google 声称,该研究将大大提高训练速度和能效,比其他方法的性能高出 13 倍,能效高出 10 倍。随着有关 AI 数据中心对环境影响的讨论日益升温,新的 JEST...……更多
2024-07-11 09:47:00赛道,训练,方法,数据,模型,学习

...为刘家铭博士,研究方向为面向开放世界的多模态具身大模型与持续性学习技术。本工作第二作者为刘梦真,研究方向为视觉基础模型与机器人操纵。指导老师为仉尚航,北京大学计算机学院研究员、博士生导师、博雅青年学者...……更多
2024-06-21 09:52:00机器,模态,人多,机器人,推理,北大
...e Information 的一篇文章。这篇文章透露,OpenAI 下一代旗舰模型的质量提升幅度不及前两款旗舰模型之间的质量提升,因为高质量文本和其他数据的供应量正在减少,原本的 Scaling Law(用更多的数据训练更大的模型)可能无以为继...……更多
2024-11-27 13:32:00潜力,模型,图像,起点,领域,还是

...读】DIAMOND是一种新型的强化学习智能体,在一个由扩散模型构建的虚拟世界中进行训练,能够以更高效率学习和掌握各种任务。在Atari 100k基准测试中,DIAMOND的平均得分超越了人类玩家,证明了其在模拟复杂环境中处理细节和进...……更多
2024-11-19 09:49:00模型,训练,小时,学习,世界,模型

...点在于,Llama 3.2成为羊驼家族中,首个支持多模态能力的模型。Connect大会上,新出炉的Llama 3.2包含了小型(11B)和中型(90B)两种版本的主要视觉模型。正如Meta所说,这两款模型能够直接替代,相对应的文本模型,而且在图像...……更多
2024-09-27 13:39:00模态,宝宝,模型,图像,训练,文本

...态连续学习的最新进展连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前...……更多
2024-11-14 09:46:00模态,清华,中文,联合,学习,模态

...又又动荡了,另一边被誉为「真・Open AI」的 Meta 对 Llama 模型来了一波大更新:不仅推出了支持图像推理任务的新一代 Llama 11B 和 90B 模型,还发布了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。不仅如此,Meta 还...……更多
2024-09-27 13:42:00推理,可在,图像,运行,版本,支持

【新智元导读】NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。文本...……更多
2024-09-24 13:36:00英伟,模态,文本,性能,模态,模型

...又多了一个选择!今日,腾讯宣布旗下的混元视频生成大模型(HunYuan-Video )对外开源,模型参数量 130 亿,可供企业与个人开发者免费使用。目前该模型已上线腾讯元宝 APP,用户可在 AI 应用中的「AI 视频」板块申请试用。腾讯...……更多
2024-12-04 09:48:00文生,腾讯,模型,参数,社区,视频

...可扩展图像),论文一作为田柯宇(此前因涉攻击内部大模型,被字节起诉)。参见机器之心报道《GPT 超越扩散、视觉生成 Scaling Law 时刻!北大 & 字节提出 VAR 范式》。机器之心获悉,从 2023 年开始,字节商业化技术团队就...……更多
2024-12-05 09:47:00论文,清华,亚军,字节,北大,模型

...凌晨,OpenAI再次扔出一枚深水炸弹,发布了首个文生视频模型Sora。据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。目前官网上已经更新了48个视频demo,在这...……更多
2024-02-16 18:44:00文生,奥尔,奥尔特曼,特曼,模型,提示

清华大学计算机系讲席教授、人工智能研究院基础模型研究中心主任唐杰出品|搜狐科技作者|郑松毅2024年已过半,大模型之争热度不减,通往AGI的路究竟该怎么走?近日,清华大学计算机系讲席教授、人工智能研究院基础模...……更多
2024-06-05 18:36:00清华,模型,教授,性能,方法,模型

...智元了解,字节商业化技术团队早在去年就把视觉自回归模型作为重要的研究方向,团队规划了VAR为高优项目,投入研究小组和大量资源。
除了VAR,团队还发表了LlamaGen等相关技术论文,新的研究成果也将在近期陆续放出。事...……更多
2024-12-05 09:47:00实习生,下巴,字节,实习,论文,模型

在当今多模态领域,CLIP 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。CLIP 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。然而,CLIP 的文本处理能力被广...……更多
2024-11-28 09:59:00模态,教会,文本,升级,数据,模态

一个5月份完成训练的大模型,无法对《黑神话·悟空》游戏内容相关问题给出准确回答。这是大模型的老毛病了。因为《黑神话》8月才上市,训练数据里没有它的相关知识。众所周知,大模型的训练和微调会消耗大量计算资源...……更多
2024-11-11 13:34:00模态,接入,框架,模型,效果,互联网
...暴增上千关注的,前所未见!”当DeepSeekR1方法遇上视觉模型会有什么新变化?“这个项目的灵感来自DeepSeek R1方法,其通过GRPO(Group Relative Policy Optimization)强化学习方法,在纯文本大模型上取得了显著效果。”赵天成表示。他...……更多
2025-02-26 07:07:00杭州,推理,模型,视觉,又是,全球

字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation Col...……更多
2024-11-08 09:47:00残差,豆包,收敛,字节,模型,团队

今日值得关注的大模型前沿论文SwiftEdit:50 倍速文本引导图像编辑清华团队提出大模型“密度定律”足球领域首个视觉语言基础模型Aguvis:首个完全自主的纯视觉 GUI agentGoogle DeepMind:利用运动轨迹控制视频生成大模型数学新基...……更多
2024-12-10 09:53:00模型,语言基础,清华,定律,密度,团队

...武静静编辑|邓咏仪放弃造车后的苹果,正在加速入局大模型战争。当地时间3月15日,苹果就披露了两个关键大模型动作。其中一个值得关注的是苹果的收购事件。彭博社报道称,苹果已经收购了一家加拿大AI初创公司DarwinAI。...……更多
2024-03-16 18:14:00模型,苹果,参数,焦点,分析,公司

...构成威胁,Arm 和台积电将获胜。”有网友说到苹果在大模型发展上的状况。也有网友认为,苹果在大模型上的发力将为其在未来的手机市场竞争中带来优势。他们认为,开源模型加上移动设备的本地数据,即本地化的原生 LLM,...……更多
2023-12-26 14:06:00模型,生态,模态,零碎,苹果,模型

只要改一行代码,就能让大模型训练效率提升至1.47倍。拥有得州大学奥斯汀分校背景四名华人学者,提出了大模型训练优化器Cautious Optimizers。在提速的同时,Cautious能够保证训练效果不出现损失,而且语言和视觉模型都适用。...……更多
2024-11-28 09:58:00训练,模型,团队,速度,代码,华人
更多关于科技的资讯:
“张叔叔,这银行卡的密码可不能随便告诉别人,就连短信验证码也得藏好,那可是您账户的‘第二把钥匙’”。中信银行石家庄分行网点工作人员一边为70多岁的张叔叔递上一杯水
2025-12-02 10:21:00

2025年11月27至29日,由全国卫生产业企业管理协会医院后勤管理发展分会主办的2025年学术会议在杭州召开。中国移动受邀参加“新质生产力助力医院后勤高质量发展”主论坛
2025-12-02 11:03:00

“具身智能是AI赛道中的焦点,其商业化更依赖技术平台、场景适配与生态协同。腾讯云愿意提供全栈AI服务能力,助力具身智能赛道与广大企业共同发展
2025-12-02 11:03:00
在大健康消费升级与抗衰需求爆发的今天,麦角硫因作为“线粒体级”超级抗氧化剂,已成为膳食补充剂领域的核心赛道。据天猫国际发布的《2023全球超级成分趋势白皮书》显示
2025-12-02 11:31:00
企业数字化转型不断深化,业务系统的可用性、数据安全性和架构弹性正成为企业核心竞争力的重要组成部分。云服务器作为企业 IT 基础设施的底座
2025-12-02 11:42:00
11月21日,富德生命人寿保险股份有限公司在河北石家庄举行以“全维健康守护 创造美好生活”为主题的健康险产品矩阵暨服务升级发布会
2025-12-02 12:11:00
GeneIII仅三麦角硫因胶囊凭借 99.99% 行业顶尖纯度、原生生物合成技术壁垒、三甲医院人体临床验证背书,成为兼具安全性
2025-12-02 14:27:00

步入繁华的商业街区,不难发现一个耐人寻味的现象:店铺橱窗中的传统文化元素,正以近乎重复的方式不断上演。印着汉字 logo 的T恤
2025-12-02 14:35:00


鲁网12月2日讯2026年美加墨男足世界杯分组抽签仪式将于当地时间12月5日在美国华盛顿举行。同日,五粮液FIFA2026世界杯官方联名款产品将在京东直播间重磅首发上市
2025-12-02 15:36:00

当AI逐渐褪去神秘面纱,谁是这场技术变革真正的操盘手?答案是:一线业务人。 近日,首届「飞书AI效率先锋全国大赛」华东赛区半决赛圆满收官
2025-12-02 15:58:00
中新经纬12月2日电 题:即时零售不再打“补贴战”了作者 江瀚 盘古智库高级研究员随着资本耐心减弱,单纯依赖补贴拉动的增长已难以为继
2025-12-02 16:09:00

近期,一款具备“定点扫测”功能的国产化三维图像声呐,凭借细腻的图像和独有的成像方式,成为声呐应用领域的“新质生产力”。国产三维搜索声呐破局者“HDY-3DL”来自海底鹰深海科技的三维搜索声呐HDY-3DL
2025-12-02 16:13:00

近日,为深化产教融合,推动科技兴农战略落地,烟台职业学院经贸系师生团队一行6人赴烟台栖霞、牟平、高新等地的多家农产品加工企业开展实地调研与合作洽谈
2025-12-02 16:16:00

鲁网12月2日讯11月27日,第三届济南科技金融论坛在山东大厦成功举办。本届论坛由财新传媒主办、齐鲁银行承办,以“科技金融 深度赋能”为主题
2025-12-02 16:48:00