- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...故事生成等新能力架构:视觉部分使用切图策略支持动态分辨率图像,语言部分采用 MoE 架构低成本高性能训练:继承 DeepSeek-VL 的三阶段训练流程,同时通过负载均衡适配图像切片数量不定的困难,对图像和文本数据使用不同流...……更多
2024-12-16 09:33:00模型,视觉,时代,模型,图像,分辨率

...的研究,可能推动新一代规模更大的模型的发展。
更高分辨率的多模态学习最近,大型视觉语言模型在其更大的模型中使用预训练的图像编码器,其中一些使用监督分类进行预训练(如PaLI,PaLI-X,Flamingo,PaLM-E),一些使用预...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型

...无法直接进行模型对比和研究。并且,不同模型在处理高分辨率图像输入时的设计(如动态高分辨率)虽然可以提高了与OCR相关的任务(例如,OCRBench)的性能,但与低分辨率版本模型相比,在推理相关任务(例如,MMMU)上的准...……更多
2024-09-24 13:36:00英伟,模态,文本,性能,模态,模型

...,相比上代模型,Qwen2-VL 的基础性能全面提升:读懂不同分辨率和不同长宽比的图片,在 DocVQA、RealWorldQA、MTVQA 等基准测试创下全球领先的表现;
理解 20 分钟以上长视频,支持基于视频的问答、对话和内容创作等应用;
具备...……更多
2024-09-03 09:45:00二代,通义,阿里,模型,视觉,语言

...为了解决Transformer架构核心组件注意力机制的长文本、高分辨率图像处理等问题,扩散模型用可扩展性更强的状态空间模型(SSM)主干替代了传统架构中的注意力机制,可以使用更少的算力,生成高分辨率图像。此前Midjourney与Sta...……更多
2024-02-16 18:44:00文生,奥尔,奥尔特曼,特曼,模型,提示

...了一个全新的视觉编码器。基于此,Pixtral 12B输入图片的分辨率和长宽比不受任何限制,并且在128K的上下文窗口范围内,想放多少张图片都行!从论文的测试结果来看,Pixtral 12B明显优于其他类似大小的开源模型(比如Llama-3.2 11B...……更多
2024-11-20 09:43:00模态,竞技场,竞技,报告,技术,模态

...解了传统图像切分策略带来的锯齿效应,提升了模型在高分辨率图像处理和文档理解任务的性能。它在多项基准测试中取得了领先的成绩,证明了其在多模态理解和文档智能领域的潜力。最近,提升多模态大模型处理高分辨率图...……更多
2024-08-13 09:42:00模态,华南,专治,后遗症,理工,分辨率

...几何形状非常有价值。Meta公司表示该模型可原生支持1K高分辨率推理,并且非常容易针对个别任务进行调整,只需在超过3亿张野生人类图像上对模型进行预训练即可。即使在标注数据稀缺或完全是合成数据的情况下,所生成的...……更多
2024-08-25 02:39:00模型,视觉,任务,图像,二维,模型

...回归学习,采用粗到细的「下一个尺度预测」或「下一个分辨率预测」。
这种简单直观的方法使得自回归(AR)Transformer能够快速学习视觉分布,并且具有较好的泛化能力:VAR首次使得类似GPT的AR模型在图像生成中超越了扩散Tran...……更多
2024-12-05 09:47:00实习生,下巴,字节,实习,论文,模型

...1、文本特征作为起始token map,根据起始token map生成更高分辨率的token map这不仅增强了模型对新文本场景的适应性,确保模型可以泛化到新的文本提示,从整体上保证了文本描述与生成图像之间的一致性2、在每个transformer层引入...……更多
2024-06-27 09:17:00范式,仅需,高质量,生成,模型,图像

...泉卫星发射中心发射,能满足目标识别级的遥感感知的高分辨率、视频等多种探测需求。在今年夏天京津冀地区的防汛工作中,‘珞珈二号’观测到堤防决口的影像,第一时间发布预警,帮6300余名群众当天完成转移。”动态监...……更多
2023-11-12 05:33:00模型,视觉,时代,模型,安防,视觉

...颈,尤其是对于抽象图表而言,因此未来提升编码器图像分辨率可以增强LLM的细粒度认知能力参考资料:https://the-decoder.com/study-reveals-major-weaknesses-in-ais-ability-to-understand-diagrams-and-abstract-visuals/https://arxiv……更多
2024-08-08 16:23:00模态,领衔,基准,推理,视觉,能力

...现有的Emu图像生成模型提供支持,可根据文本提示创建高分辨率图像。它目前对美国的英语用户免费使用(后续是否收费未知),并且每个提示都会生成四个图像。此前,Meta图像生成模型因带有种族偏见的图像贴纸而面临争议...……更多
2023-12-07 13:34:00建高,图像,生成器,生成,分辨率,全新

...理:动态子图方案:支持处理极端长宽比的图像,兼容高分辨率图像,展现出色的图像理解能力。3、全面数据优化:多方向数据集覆盖:全面覆盖Caption、VQA、OCR、Table、Chart等各个多模态数据方向,显著提升多模态问答、指令跟...……更多
2024-09-20 13:35:00模态,阿里,模型,能力,升级,国际

...效果苹果做了各种变量实验,通过修改数据源、修改图像分辨率等,来看各种因素对模型效果的影响。△摘自苹果发布的论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》目前,苹果发现让多模态大模型变得更聪明.……更多
2024-03-16 18:14:00模型,苹果,参数,焦点,分析,公司

...型的风格,指定镜头,建议电影效果,Veo 2都会以高达4K分辨率并延长到数分钟的视频长度来呈现。比如,要求“低角度跟踪镜头穿越场景中央”或“特写科学家通过显微镜观察”的镜头,Veo 2都能实现。提示“18mm镜头”,Veo 2知...……更多
2024-12-17 09:12:00最新版,生成,模型,更新,视频,生成

...。采用文生视频和图生视频功能生成的视频最长为5秒,分辨率最高为720P,帧率为每秒24帧。采用生成扩展功能的视频最多可延长2秒,视频背景音效延长10秒。Firefly视频模型作为Adobe生成式AI套件的扩展,已经被集成到其云端套装...……更多
2024-10-17 09:52:00公测,一键,生成,视频,现实,开放

...消融研究,STIV 尽管设计简单,却表现出了强大的性能。分辨率为 512 的 8.7B 参数模型在 VBench T2V 上达到 83.1,超过了 CogVideoX-5B、Pika、Kling 和 Gen-3 等领先的开源和闭源模型。在分辨率为 512 的 VBench I2V 任务中,同样……更多
2024-12-13 09:19:00推理,模型,思维,空间,模型,生成

...o-SALMONN模型通过三部分创新:音视频编码和时间对齐、多分辨率因果Q-Former、多样性损失函数和混合未配对音视频数据训练。该模型不仅在单一模态任务上表现优异,更在视听联合任务中展现了卓越的性能,证明了其全面性和准...……更多
2024-08-01 09:45:00模态,清华,领衔,模型,视频,音视

...构创新,具备了惊人的图像生成速度,而且最高能实现4k分辨率。一台16GB的4090笔记本,仅需0.37秒,直接吐出1024×1024像素图片。如此神速AI生图工具,竟是出自英伟达MIT清华全华人团队之笔!正如其名字一样,Sana能以惊人速度合...……更多
2024-10-18 09:49:00英伟,清华,架构,大片,性能,笔记本

...的视频。从官方介绍中看,此次主要有三个方面的升级。分辨率能达到4K;能够理解有关镜头控制的Prompt;更注重现实物理世界与人类表情的理解和展示。在官方账号底下,大家都对这些效果表示了惊叹:我真的想谷歌输掉比赛...……更多
2024-12-17 09:12:00海螺,高清,一句话,镜头,升级,控制
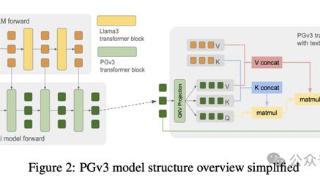
...束位置ID固定后,在中间插值位置ID,不过该方法在训练分辨率上严重过拟合,并且无法泛化到未见过的纵横比。相比之下,「扩展-PE」(expand-PE)方法按序列长度成比例增加位置ID,不使用任何技巧或归一化,性能表现良好,没...……更多
2024-10-08 09:48:00文生,图形设计,深度,图形,人类,参数

...片信息并转化成文字答案。升级后的LLaVa-1.6对输入图像的分辨率提升到原来的4倍以上,使得模型能够抓住图片的更多细节。目前支持的图像分辨率有672x672、336x1344以及1344x336三种。LLaVA模型架构基于大量的图像-文本配对的数据集...……更多
2024-02-10 21:04:00性能,模型,模态,训练,数据,卷上

...数量是StyleGAN3的3倍,基于ImageNet训练,能生成1024×1024高分辨率的图像,并借鉴了StyleGAN2和StyleGAN3的部分架构设计。它的整体架构如下:具体到细节上,作者们对生成器、判别器和文本对齐权衡机制进行了重新设计,用FID对样本...……更多
2023-02-01 14:22:00英伟,生成,图像,模型,作者,英伟

...型能够以线性复杂度实现有效的序列建模,在长文本、高分辨率图像、视频等长序列建模和生成领域表现出很大的潜力。
然而,Mamba 并不是第一个实现线性复杂度全局建模的模型。早期的线性注意力使用线性归一化代替 Softmax ...……更多
2024-12-11 09:53:00阿里,清华,线性,视角,注意力,模型

...据需求向精细化、场景化发展,需要使用更大像素、更高分辨率的图像以提供丰富细致的信息进行训练和推理,标注数据的规模和复杂性也随之增加。如何提高超大像素图像数据标注的效率和精度,成为当前亟待解决的问题。例...……更多
2023-10-25 19:02:00精度,像素,图像,效率,能力,科技

...b/main/assets/hunyuanvideo.pdf二、腾讯混元的下一步:提高视频分辨率和生成速度腾讯混元多模态生成技术负责人凯撒谈道,文生视频与图像生成在技术上有着密切联系。虽然视频生成建立在图像生成的基础上,但它对动态时序信息和...……更多
2024-12-04 09:49:00文生,腾讯,提示,建议,视频,生成

...同,EmuVideo更简单,仅使用2个扩散模型,就能生成512x512分辨率、每秒16FPS、长4秒钟的视频。IT之家发现,Meta援引评估数据,证明EmuVideo生成的视频品质以及“遵循提示词的忠实程度”相对业内竞品更好。在品质方面,有96%受访...……更多
2023-11-20 11:38:00图像编辑,图像,工具,生成,图像,模型

...使用BEV大模型+占用网络方案,小米的创新点在于通过超分辨率技术实现感知精度的提升,并且提升BEV大模型的感知范围与精度。实质上,小米则是加强了Orin-X芯片的AI处理份额占比,用AI超分辨率计算做高精度感知。超分辨率占...……更多
2024-01-05 00:18:00小米,场景,分辨率,原因,技术,小米
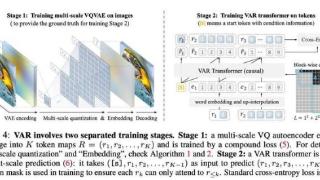
...升 ImageNet 生成效果。他们使用公开可用的网络,为 64×64 分辨率下的生成创造了 1.01 的 FID 记录,为 512×512 创造了 1.25 的 FID 记录。此外,该方法也适用于无条件扩散模型,可极大提高其质量。 ……更多
2024-12-05 09:47:00论文,清华,亚军,字节,北大,模型
更多关于科技的资讯:

12月2日,法国巴黎,在欧洲食品科技领域最具影响力的盛会——欧洲食品配料展(Food Ingredients Europe
2025-12-07 16:44:00
当城市核心区的物理空间增长几近饱和,未来的竞争力新高地何在?12月5日,一场发布会以别开生面的“数字气味”体验开场,为上城区加快建设中央创新区(CID)的战略发布
2025-12-07 07:21:00
日前,山西转型综改示范区入区企业山西恒真真空玻璃科技有限公司自主研发的新产品——“真空发热玻璃”上市。这一产品将高效真空玻璃技术与新型半导体制热技术深度融合
2025-12-07 07:32:00
生产设备共享给清河羊绒带来什么——河北特色产业集群共享智造故事(四)纱线在电脑横机上来回穿梭、电商平台的提示音此起彼伏……随着冬季来临
2025-12-06 08:04:00

市民现场体验移动随心屏(闺蜜机)的AI舌象问诊功能。厦门网讯 (文/厦门日报记者 许晓婷 王玉婷 通讯员 陈奕珣 图/厦门移动 提供)伸出舌头拍一拍
2025-12-06 08:26:00
厦门网讯 (厦门日报记者 林露虹)刷到一部微短剧,不知不觉被剧情吸引,回过神来看介绍,发现竟是AI参与制作的。类似经历
2025-12-06 08:26:00

厦门网讯 (厦门日报记者 詹文 林健华)在位于同安工业集中区的生产车间里,一节一节钢板正传送上激光切割台,自动切割、打孔
2025-12-06 08:26:00

鲁网12月5日讯近日,临沂联通与临沂电信深度践行国家共建共享战略,成功完成全省首个基于电信800M频段的5G RedCap技术承载联通物联网专网业务的商用落地
2025-12-06 13:44:00
中国青年报客户端讯(中青报·中青网记者张均斌)近日,“中央引导地方”专项科技赋能文化方向立项课题——“面向文博场景的智能伴游导览系统研发及示范应用”启动会
2025-12-06 15:25:00

在“双碳”目标引领下,校园节能改造成为教育领域绿色发展的重要方向。据住建部统计,商业建筑能耗中照明系统占比高达35%,学校作为人员密集
2025-12-06 16:09:00

12月1日,豆包手机助手技术预览版正式发布,首发搭载于中兴Nubia工程样机。豆包手机助手是以豆包APP为基础,与手机厂商在操作系统层面合作开发的AI助手软件
2025-12-06 17:41:00

历经修缮重生的丰乐剧场,以“吉林省音乐厅”之名即将绽放春城。这座历史建筑,从伪满时期影剧院到音乐剧场的跨越,背后藏着一套极致考究的声学设计方案
2025-12-06 18:41:00

“关键核心技术与高端装备对外依存度高”一直是制约制造业升级的瓶颈。五轴联动铣头作为五轴机床的核心功能部件,过去很长一段时间被欧洲部分知名厂商垄断
2025-12-06 22:07:00

鲁网12月6日讯12月6日,以“乘势向上 聚力向新”为主题的山东重工潍柴集团2026年商务大会在潍坊举行。山东重工集团党委书记
2025-12-06 22:43:00