- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
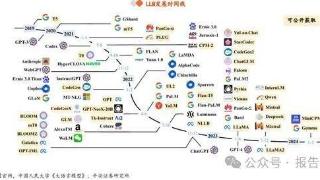
技术:大模型发展呈现“规模定律”,Transformer为技术基座1.1 大模型“大力出奇迹”的背后:Scaling Law大规模语言模型(Large Language Models,LLM)泛指具有超大规模参数或者经过超大规模数据训练所得到的语言模型。与传统语言模...……更多
2024-10-21 10:03:00模型,行业报告,新纪元,报告,发展,行业

用扩散模型搞社交信息推荐,怎么解决数据噪声难题?现有的一些自监督学习方法效果还是有限。针对此,港大数据智能实验室提出了新项目RecDiff。RecDiff是一种全新的基于扩散模型的推荐框架,能够更好地捕捉用户的潜在偏好...……更多
2024-07-30 09:31:00社交,实验室,模型,实验,智能,数据

...学生怎么办?CMU清华团队提出了Lean-STaR训练框架,在语言模型进行推理的每一步中都植入CoT,提升了模型的定理证明能力,成为miniF2F上的新SOTA。如果想训练LLM证明定理的能力,你会怎么做?既然模型可以通过海量语料学会生成...……更多
2024-08-10 09:47:00顶新,成数,清华,模型,训练,高手

...要,但其作用可能被夸大了。大家思考一个问题,产品/模型是否会因为用户数据越多,而变得更好?还是存在一个S曲线?先不说ChatGPT4.0“变懒”。事实上,训练模型可能并不需要更多的数据,达到一定程度就足够了。例如,A16...……更多
2024-02-18 14:13:00效应,增长,时代,网络,摩尔,定律
...外版美国斯坦福大学等机构研究团队近日宣布,在基座大模型基础上,仅耗费数十美元就开发出相对成熟的推理模型。尽管其整体性能尚无法比肩美国开放人工智能研究中心(OpenAI)开发的o1、中国深度求索公司的DeepSeek-R1等,...……更多
2025-02-27 05:08:00范式,模型,科研,团队,成本,全球

...领域。自从AI赛道大热以来,人们的关注点主要在各种大模型的竞争,OpenAI、谷歌、Meta等巨头和各种初创企业在软件层面“争奇斗艳”。而在硬件层面,似乎英伟达已经“一骑绝尘”,该公司生产的GPU芯片“一片难求”,全球AI...……更多
2024-02-22 16:46:00英伟,豪言,创始人,芯片,成本,速度

成本不到150元,训练出一个媲美DeepSeek-R1和OpenAI o1的推理模型?!这不是洋葱新闻,而是AI教母李飞飞、斯坦福大学、华盛顿大学、艾伦人工智能实验室等携手推出的最新杰作:s1。在数学和编程能力的评测集上,s1的表现比肩Dee...……更多
2025-02-07 15:14:00推理,模型,成本,模型,团队,推理
苹果最新杀入开源大模型战场,而且比其他公司更开放。推出7B模型,不仅效果与Llama 3 8B相当,而且一次性开源了全部训练过程和资源。要知道,不久前Nature杂志编辑Elizabeth Gibney还撰文批评:许多声称开源的AI模型,实际上在...……更多
2024-07-23 09:33:00苹果,一口,模型,一口气,训练,过程

...方面。首先介绍的的是近期大热的AI,OPPO首个自助训练大模型平台——安第斯大模型正式亮相。据悉,全新的AndesGPT首次应用70亿参数的大模型,相比10亿大模型,同时更大的模型数据量,在AI处理的能力方面会更好,并且这次大...……更多
2023-12-28 02:13:00突破,三大,技术,模型,背景,技术
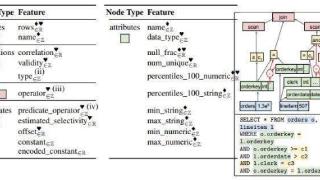
...用的基数估计技术,依赖于启发式(Heuristic)方法和简化模型,例如假设数据统一和列独立。这些方法虽然计算效率高,但往往需要准确预测基数,在涉及多个表和过滤器的复杂查询中表现尤为明显。最新的数据驱动方法试图在...……更多
2024-09-04 09:48:00框架,评估,数据,模型,基准,查询

...为提升其聊天机器人产品Gemini的性能而努力,该公司希望模型性能提升的速度可以与去年相当,这促使研究人员专注于其他方法来勉强取得效果。这种情况和OpenAI的遭遇类似。此前有报道称,OpenAI模型性能提升速度有所放缓,该...……更多
2024-11-15 09:51:00立新,团队,员工,速度,问题,模型

...值向量,进而利用监督学习的方法进行训练。通过训练,模型能够学习到从文本到类别的映射关系,从而实现对新文本的自动分类。这些算法在垃圾邮件识别、新闻分类、情感分析等领域有着广泛的应用。关键词:TF-IDF;决策树...……更多
2024-08-26 09:59:00性能分析,算法,电子邮件,性能,常见,邮件

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。据外媒The Information报道,Meta的开源大模型Llama 3一直难以在全球最大云厂商——亚马逊的AWS上获得关注,AWS的企业客户更倾向于使用Anthropic...……更多
2024-08-28 09:44:00业内人士,模型,业内,根本,人士,成本

...全资子公司安徽寒武纪信息科技有限公司“一种神经网络模型的量化训练方法、装置及设备”专利获授权。企查查专利摘要显示,该方法包括:在正向传播过程中,获取待量化层的第一输入数据和参数;分别对第一输入数据和参...……更多
2025-09-15 10:00:00神经网络,模型,神经,训练,专利,方法

...达的垄断地位。而AMD的MI300,在部署32K上下文窗口的GPT-4模型时,居然比H100效果更好?AI芯片大决战,即将来临!AI硬件开发商初创公司的未来会怎样?Tenstorrent CEO David Bennett直言不讳地表示,在我们这个行业,大部分初创公司的...……更多
2023-11-06 15:12:00英伟,大决战,芯片,性能,英伟,芯片

新眸原创·作者|桑明强当全球科技巨头为AI大模型疯狂加码GPU算力时,一家头部券商公司却公开诉苦:费力搭建的GPU集群,利用率却始终卡在30%,算力空转导致每月仅电费就是一笔不小的开销,核心瓶颈竟然是一块“看不见的短...……更多
2025-04-08 17:41:00焦虑,模型,时代,存储,京东,数据

...再次刷新端侧多模态天花板,面壁「小钢炮」 MiniCPM-V 2.6 模型重磅上新!仅8B参数,取得 20B 以下单图、多图、视频理解 3 SOTA 成绩,一举将端侧AI多模态能力拉升至全面对标超越 GPT-4V 水平。更有多项功能首次上「端」:小钢炮...……更多
2024-08-07 09:42:00多图,小钢炮,模态,上端,手机,视频

【新智元导读】UrbanGPT是一种创新的时空大型语言模型,它通过结合时空依赖编码器和指令微调技术,展现出在多种城市任务中卓越的泛化能力和预测精度。这项技术突破了传统模型对大量标记数据的依赖,即使在数据稀缺的情...……更多
2024-08-01 09:40:00时空,华南,样本,理工,模型,时空

出品 | 搜狐科技作者 | 梁昌均编辑 | 杨锦一口气开源8款模型,阿里通义又上新!4月29日一大早,阿里开源发布Qwen3,包括两款MoE(混合专家架构)模型,其中具备2350亿参数规模的Qwen3-235B-A22B,在对比测试中成为目前最强大的开...……更多
2025-04-29 16:17:00模型,阿里,话语权,中国,话语,全球

...爆全球AI浪潮以来,AI圈子已经迅速走过了造出了通用大模型的第一道关卡,如今最关键的问题在于——如何让大模型高效地在实际应用场景中落地?百川智能的最新实践是:用大模型+增强技术,可以大大提升企业应用大模型的...……更多
2023-12-21 15:32:00百川,外挂,模型,成本,硬盘,智能

...况,这一举动引起了业界的广泛关注。然而,在视觉语言模型的角逐中,谷歌也不甘示弱。
近日,Google Research、Google DeepMind 和 Google Cloud 共同推出了一个更小、更快、更强大的视觉语言模型(VLM)——PaLI-3,该模型与相似的体...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型

...飞跃。
英特尔Gaudi3预计可大幅缩短70亿和130亿参数Llama2模型,以及1750亿参数GPT-3模型的训练时间。此外,在Llama7B、70B和Falcon180B大语言模型(LLM)的推理吞吐量和能效方面也展现了出色性能。英特尔Gaudi3提供开放的、基于社区的...……更多
2024-04-10 17:08:00英特,英特尔,软硬,全新,平台,企业

...临着很多痛点,比如终端内存限制、端侧生成速率以及大模型数量受限等。为此发哥通过多项技术上的突破,成功解决了这些痛点。首先是大模型对于手机内存占用的问题,以130亿参数大模型为例,正常情况下它所需的内存为13G...……更多
2023-11-08 09:36:00联发,天玑,旗舰,性能,体验,时代

大模型的上下文长度快速增长,超长上下文解锁新应用,但推理计算代价高昂,上下文本身对于信息不会进行压缩,不能直接捕捉其中的深层知识和规律。上海人工智能实验室领军科学家林达华。过去一年,人工智能领域风起...……更多
2024-03-25 10:53:00林达,模型,之路,结构,发展,模型

11月11日,海外媒体表示OpenAI即将推出的新旗舰模型“Orion”在性能上的提升幅度不及预期。与GPT-3到GPT-4的显著进步相比,Orion相较于GPT-4的提升显得微不足道。Orion和GPT-4均基于变压器架构,但在设计上有所区别。GPT-4作为GPT-3的...……更多
2024-11-13 03:51:00旗舰,模型,性能,模型,训练,进步

...开发者大会上,推出两款定制芯片,以应对不断增加的大模型训练成本挑战,并试图降低提供AI服务的成本。微软表示,新发布的芯片不会出售,仅供支持自己的产品,并作为微软云Azure云计算服务的一部分。微软最新推出的两...……更多
2023-11-16 23:46:00英伟,芯片,一家,芯片,英伟,微软

1月29日,百川智能发布超千亿参数的大语言模型Baichuan3。在多个权威通用能力评测如CMMLU、GAOKAO和AGI-Eval中,Baichuan3都展现了出色的能力,尤其在中文任务上更是超越了GPT-4。而在数学和代码专项评测如MATH、HumanEval和MBPP中同样表...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川
...)的方法,并通过一系列技术策略,最大程度地优化了大模型推理系统,实现了惊人的性能和效率。具体而言,在更大的吞吐的方面,大规模跨节点专家并行能够使得batch size(批尺寸)大大增加,从而提高GPU矩阵乘法的效率,...……更多
2025-03-01 18:59:00利润率,利润,成本,理论,节点,模型
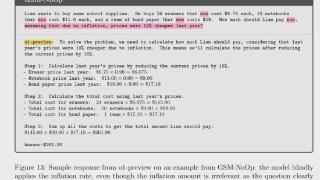
苹果新论文:AI 大模型可能不会推理。AI 大模型(LLM)真的像我们理解的那样能「思考」或「推理」吗?最近,苹果的一篇论文探讨了这个问题,并且给出了一个倾向于「否」的答案。相关帖子被很多人围观。这篇题为「GSM-Symb...……更多
2024-10-14 09:55:00数学题,推理,废话,苹果,数学,小学

...进行文献搜索和文献综述工作,而且做到了数据、代码、模型权重的全方位开源。LLM集成到搜索引擎中,可以说是当下AI产品的一个热门落地方向。前有Perplexity横空出世,后有谷歌Gemini和OpenAI的SearchGPT纷纷加入。就在11月23日,...……更多
2024-11-27 13:33:00神器,文献,效率,科研,学术,模型
更多关于科技的资讯:
江南时报讯 在金融科技迅猛发展和客户需求持续升级的背景下,南通农商银行积极推动转型升级,以网点转型为核心,通过创新管理模式
2025-12-02 21:24:00
江南时报讯 近日,南通农商银行远程视频银行密码重置功能正式上线,当日即为两名客户顺利完成业务办理。这标志着该行在“远程银行”金融服务领域迈出关键一步
2025-12-02 21:24:00

11月5日,迈萨科机械科技(常州)有限公司正式开业,这标志着全球工业混合技术领域的隐形冠军——德国迈萨科公司在中国市场布局迈出关键一步
2025-12-02 21:50:00


近日,在第八届中国国际进口博览会期间,“2025知识产权保护与企业国际化发展会议暨‘百链千企’专利产业化工程推进会”在上海举行
2025-12-02 22:20:00

12月2日,千问APP接入万相系列最新模型Wan2.5,视频创作能力再度升级。动作精度和肢体协调性全面提升,并成为首个支持音视频同时输出的移动端AI助手
2025-12-02 22:37:00

胶东在线12月1日讯 11月17日,在烟台金融监管分局指导下,《烟台市保险业整治“内卷式”竞争自律公约》(以下简称《公约》)正式发布
2025-12-02 19:54:00
12月2日,太重集团发布消息,由太重集团自主设计制造的6000UST(美吨)正向双动铜挤压机热试车圆满成功。这台堪称国内最大
2025-12-02 19:29:00

11月28日,AI驭见未来——怡海教育&加州伯克利大学机器人自动驾驶大赛ROAR实训基地揭牌仪式在北京市丰台区怡海中学(北校区)举行
2025-12-02 12:04:00
●杨炯上周末,在珠海的亚洲通航展上,奥捷龙航空科技有限公司格外引人注目。虽然已多次到珠海参展,但这次它“来自厦门”。这一全球市场份额第一的德国旋翼机品牌
2025-12-02 08:18:00

视障文化博物馆“触摸文明”展厅。中青报·中青网记者 李怡蒙/摄如今,许多博物馆将视觉、听觉、触觉等多种感知方式融合,创造出多层次
2025-12-02 05:43:00

摘要:本文分析现代物流网络布局与供应链弹性提升的内在关联,探讨节点布局合理性、线路连接多样性、资源整合协同性对供应链冗余能力
2025-12-02 07:09:00
摘要:本文聚焦管理会计在企业战略决策中的应用,首先解析其与战略决策的内在关联,即通过整合财务与非财务信息,为战略制定提供系统性支持
2025-12-02 07:10:00