- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...要对是否响应以及如何响应请求做出细微差别。如果说明不够明确,注释者可能不得不依赖个人偏见,从而导致超出预期的模型行为,如变得过于谨慎,或以不理想的风格(如评判)做出响应。例如,在 OpenAI 的一次实验中,一...……更多
2024-07-26 09:35:00不够,奖励,机制,设计,模型,安全

...模型解决复杂问题的能力,尤其是在 o1 所采用的细粒度奖励机制的加持下。这种奖励机制为模型的每一步推理提供细粒度的反馈,而不仅是依赖最终答案的正确性来评估模型的表现。通过精细化的控制,使模型能够不断优化其...……更多
2024-10-26 09:48:00算法,奖励,理念,问题,技术,模型

...penAI 安全团队发布了一项新的研究成果,发现基于规则的奖励可用于提升语言模型的安全性。这不由得让人想到了科幻作家艾萨克・阿西莫夫提出的「机器人三定律」和作为补充的「机器人第零定律」,这就相当于用自然语言给...……更多
2024-11-07 09:54:00定律,机器人,模型,规则,机器,安全

...他看来,未来世界模型需要新的算法机制,应该更加关注奖励组合的设计,不仅包括外部环境给予的奖励,也包含模拟对于人类追寻好奇心的内部奖励。通过奖励机制组合优化模型不仅能让模型追寻外部目标,也能让AI理解科学...……更多
2024-07-08 09:54:00爱因斯坦,智能,人工智能,人工,科学,人工智能

...费将自动转换为购买CMC,并通过销毁代币方式实现CMC算力奖励。这一机制不仅简化了上币流程,还增加了CMC的市场需求,确保了其价值的持续增长。此外,持有一定数量CMC的经纪人可以解锁IEO白名单特权,获得参与优质项目初始...……更多
2024-06-12 15:35:00交易所,极致,模型,哲学,交易,设计

...性,激励社区成员积极参与价值建设。25%生态发展(算力奖励):这部分代币直接打入黑洞地址,换成算力作为奖励支持生态发展,促进社区成员的参与和贡献。10%社区建设(算力奖励):用于鼓励社区新成员参与,部分代币作...……更多
2024-06-18 13:30:00一文,台币,交易所,交易,代币,交易

...励社区成员积极参与CMC价值建设。25%用于生态发展(算力奖励),这些代币将作为原生代币打入黑洞地址,换成算力支持生态发展。生态的算力奖励的目标是促进社区成员的参与和贡献,以推动项目的发展和完善。10%用于社区建...……更多
2024-06-14 17:28:00币种,交易所,初衷,对话,交易,代币

【新智元导读】Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。LLM对数据的大量消耗,不仅体现在预训练语料上,还体现在RLHF、DPO等对齐阶段...……更多
2024-08-01 09:40:00三角,进化,模型,奖励,训练,迭代

...」。
训练时,AI agent在环境中不断观察并行动,并得到奖励模型的反馈进行自我改进。但比较特别的是,奖励函数是由拟合人类反馈得到的。2019年,这项技术被用到了NLP领域,用于微调语言模型。论文地址:https://arxiv.org/abs/190...……更多
2024-08-10 13:48:00后腿,秘方,人类,奖励,模型,学习

...境,它需要做出一系列动作或决策,以最大化从环境获得的奖励。这种概念贯穿于我们的日常生活,比如一个人从A点开车到B点,他需要在每个路口做出正确的转向、刹车等决策,以最小化行驶时间(即最大化奖励)。在训练小狗的场景中...……更多
2024-04-22 11:37:00分布式,高品质,实践,亚马,亚马逊,训练

...jianguanthu.github.io/
AI Agent 的「三大短板」:为什么它们还不够「聪明」?想让 AI Agent 真正胜任助手角色,仅有海量知识是远远不够的。研究团队通过深入分析发现,当前 AI Agent 普遍存在三大短板:黑盒思维」:与优秀人类助手...……更多
2024-12-11 09:53:00清华,学徒,蚂蚁,不够,团队,怎么办

...器则是为了最大化这个值,即当前策略和最优策略之间的奖励之差为:在纳什均衡下,之前已有研究表明:
然而,如果无法获得真正的最优策略,就必须近似后悔值。利用随机策略和奖励信号,该团队设计了基于优势的代理函...……更多
2024-11-06 09:44:00框架,人类,问题,提示,策略,模型
...0万美元的比特币、BAYCNFT和5天的豪华假期等。这种创新的奖励模式吸引了大量玩家的关注和参与,让他们争夺属于他们的幸运时刻。二、解密幸运方块LuckyBlock的财富奥秘幸运方块LuckyBlock的幸运方块机制背后,是一套经过精心设...……更多
2024-02-22 15:11:00加密,幸运,方块,奥秘,财富,方块

...模型自身,当模型自身无法准确分辨偏好、所具有的知识不够强大的时候,它所提供的反馈可能不够精准或者没用导致所更新的模型的分布无法向着目标分布更新。为了解决上述问题,来自UNC ,芝加哥大学,UMD和罗格斯大学的研...……更多
2024-06-21 09:21:00模态,美国,瓶颈,顶尖,模型,团队
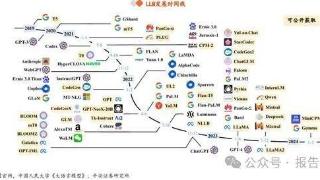
...的结果反馈给模型,让模型从两种反馈模式——人类评价奖励和环境奖励中学习策略,对模型进行持续迭代式微调。GPT-4系列:能力跃升,增加多模态能力,最新版4o突破性价比GPT系列模型的技术演变(GPT-4~GPT-4o):继ChatGPT后,O...……更多
2024-10-21 10:03:00模型,行业报告,新纪元,报告,发展,行业

...例且实际完成合同额超过2000万元的,予以一次性100万元奖励。(责任单位:新一代信息技术产业专班)4.加强核心技术攻关。支持前沿性、颠覆性技术研究,鼓励企业面向大模型基础架构、关键算法、数据技术、人工智能芯片、...……更多
2024-03-29 16:42:00开区,高地,北京,产业,人工智能,智能

济宁太白湖新区聚焦事业单位绩效工资管理存在的方案不够科学、程序不够严谨、落实不够到位、监督不够精准等突出问题,不断优化绩效工资管理机制,激发事业单位人员干事创业活力动力。突出“整体把控”,抓好顶层设...……更多
2024-10-24 15:37:00太白,干事,绩效,新区,事业单位,热情
...二级单位予以表扬。采取约谈问责机制。对宣传教育重视不够、落实不到位、发案率较高的二级单位主要负责人,由学校分管领导正式约谈。 ……更多
2023-10-16 11:39:00潍坊,校园建设,平安,机制,校园,建设
...“先进优先”的原则评选推荐,荣誉表彰的激励效应释放不够及时也不够充分。为此,该旅党委班子统一思想认识,“谁对战斗力贡献率大谁立功”,下决心立起向战为战的鲜明导向。党委经过反复思考,在全旅内推行“立功即...……更多
2024-01-26 05:27:00激励机制,机制,党委,二等功,一名,荣誉

...成的评论,令初始模型针对自身的 response 进行修正。3. 奖励建模:将修正后的 response 与原先的 response 拼接,组成偏序对,进行奖励建模,或是 DPO 微调。4. 强化学习微调:基于训练好的奖励模型,完成完整的强化学习微调流程...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...指出,目前Sora可以用来解决一些创意辅助的场景,但是不够可靠,所以应用的场景是受限的。OpenAI公司坦承,目前Sora模型也有弱点。它可能难以准确模拟复杂场景的物理特性,且可能无法理解因果关系。例如,该系统最近生成...……更多
2024-03-02 10:00:00场景,不够,应用,生成,视频,模型
...件、资源禀赋、历史机遇等原因,我国粮食生产区域格局不够平衡。2023年,13个粮食主产省(区)产量合计10834亿斤,占全国77.9%。7个主销省(市)产量合计597亿斤,占全国4.3%,需要大量调入粮食。一出一入,构成了国家粮食安...……更多
2024-03-07 14:40:00省际,主产区,横向,积极性,粮食,补偿

...一个 token 的预测损失是有依据的,但与下游的使用情况不够一致,而且无法推断出训练数据之外的情况。根据定义,人类的偏好是一致的,但却阻碍了在封闭系统中的学习。将这种偏好缓存到已学习的奖励模型中会使其自成一...……更多
2024-12-03 13:34:00用语,模型,限制,数据,智能,苏格拉底

...智能应用示范场景,对入选场景给予最高100万元的一次性奖励。建立人工智能技术应用场景项目库,支持企业参评省级“百个人工智能典型应用场景”,争取省级相关补助;支持企业应用人工智能技术,在研发设计、生产制造、...……更多
2024-03-30 08:39:00人形,机器人,机器,规模,应用,人工智能
...不认可管理层制定的标准,可能是他们的意愿或者主动性不够,也可能是服务能力不足;三是服务的需求与供给不相匹配。针对差距3产生的原因,可以从3个方面加以解决:一是重视服务的真实瞬间。真实瞬间是指游客在与服务...……更多
2024-05-08 06:54:00民宿,模型,质量,服务,民宿,服务

...通过与环境的交互,不断调整和优化策略以获得最大化的奖励。然而,现实环境中的风险与不确定性往往导致严重的安全问题。例如,在自动驾驶中,车辆不能因为探索策略而危及乘客的安全;在推荐系统中,推荐的内容不能带...……更多
2024-10-09 09:51:00同济,学习方法,深度,理论,方法,应用

...价、贷后管理等整个贷款决策流程中,每个环节均按照“奖励诚信、惩戒失信”的原则设计多维度评价模型;另一方面明确了在完成走访排查的八类灰名单人员后,客户经理不承担责任,按照推广户数及金额逐笔计酬。陈才康 ……更多
2023-11-05 06:05:00普惠,农贷,金融,农贷,申请人,兴化

...向记者表示:“我认为目前AI发展仅实现了有管理是远远不够,如何实现可管理,即有序、有效的,是当前面临的核心挑战。”那如何尽量规避这个问题,邹江兴说:“这就必须做到发展和治理两手都要硬,齐抓共管,不能滞后...……更多
2023-11-08 17:05:00科学,变革,范式,顶尖,科学研究,科学家

...格式、方法或超参数可带来改进。
阶段四:具有可验证奖励的强化学习。Ai2 引入了一个新的基于强化学习的后训练阶段,该阶段通过可验证奖励(而不是传统 RLHF PPO 训练中常见的奖励模型)来训练模型。他们选择了结果可验...……更多
2024-11-26 09:44:00模型,性能,训练,模型,训练,数据

本文转自:长江日报2月2日,长江设计集团2023年工作会议在武汉召开,现场颁发了科学技术突出贡献奖、青年创新英才奖、技术发明奖、科技进步奖等一系列重要奖项。杨爱明和廖仁强两名专家获集团第三届科学技术突出贡献...……更多
2023-02-04 19:09:00贡献奖,长江,第三届,科学技术,奖励,贡献
更多关于科技的资讯:

鲁网11月27日讯(记者 赵洪斌)在鲁北商业版图上,王文俊的名字与古贝春酒业紧紧相连。然而,这段长达二十余年的合作关系
2025-11-28 08:45:00
近日,广东宇太能源与河北某工业玻璃龙头企业签约,合作利用空微子发电技术降低企业电耗。该项目由玻璃企业投资,宇太能源提供技术及设备支持
2025-11-28 08:57:00

百年汽车产业大变局的必读之作。近日,由国内汽车行业资深媒体人与研究观察者杨钧博士撰写的新书《竞速未来-全球新能源汽车的崛起与挑战》一书已由中国出版集团中译出版社正式出版发行
2025-11-28 09:27:00
近日,鹏华基金发布公告,旗下科创创业人工智能ETF鹏华 (认购代码:588413)于11月28日正式发行。作为首批双创人工智能ETF中的一员
2025-11-28 10:11:00

11月28日消息,人工智能领域顶级会议NeurIPS 2025公布了论文奖,阿里通义千问团队最新研究成果从全球2万多篇投稿论文中脱颖而出
2025-11-28 11:01:00
11月24日,位于启东市南阳镇的朗峰新材料启东有限公司生产车间内,自动化生产线高速运转,一条薄如蝉翼的银色金属带材从特制喷嘴中“飞”出
2025-11-28 11:05:00

近日,济南轨道交通集团全资子公司莱芜交通发展集团成功举办财务管理及融资业务培训。本次培训由集团财务管理部部长刘文芹主持
2025-11-28 11:09:00

11月21日,在上海举办的“2025第一财经金融价值年会”上,青岛银行凭借在科技金融、绿色金融、地方经济服务及创新能力方面的突出表现
2025-11-28 11:18:00

近日,北京市参保市民就医迎来“智慧升级”——微信医保移动支付功能已在中国医学科学院、北京协和医院、北京大学人民医院等140家公立医院全面上线
2025-11-28 11:28:00

河北新闻网讯(吕若汐、齐彦红)11月18日,地球物理勘探设备供应商法国塞赛尔公司正式向河北省煤田地质局物测队交付了两套数字地震仪(激发系统)诺玛德65尼奥
2025-11-28 11:53:00
中新经纬11月28日电 北京市广电局网站消息,《北京市促进“人工智能+视听”产业高质量发展行动方案(2025-2029年)》(下称《行动方案》)近日发布
2025-11-28 11:57:00

全球领先的智能汽车科技解决方案提供商均胜电子(600699.SH / 00699.HK)正以创新驱动和全球协同,在汽车电子
2025-11-28 12:15:00

大河网讯 为给非涉密政务信息系统的开发建设加上一把“安全锁”,规范全生命周期的安全管控工作,11月27日,省行政审批政务信息管理局起草了《非涉密政务信息系统开发安全管理指南(征求意见稿)》(以下简称《征求意见稿》)
2025-11-28 14:10:00

为持续优化用户体验、丰富服务维度,吉林省民航机场集团有限公司门户网站(https//www.jlairports.com)正式迎来二次重大升级
2025-11-28 14:41:00

11月25日,一场以“商界链接创富圈层,共享‘商赢酱酒’杯中哲学,解锁中国式商务社交的‘心’语”为主题的交流会在济南成功举办
2025-11-28 14:55:00