- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
stabilityai推出stableaudioopen
类别:科技 发布时间:2024-06-07 03:03:00 来源:浅语科技
6月6日消息,StabilityAI立足StableDiffusion文生图模型,进一步向音频领域拓展,推出了StableAudioOpen,可以基于用户输入的提示词,生成高质量音频样本。

StableAudioOpen最长可以创建47秒的音乐,非常适合鼓点、乐器旋律、环境音和拟声音效,该开源模型基于transforms扩散模型(DiT),在自动编码器的潜在空间中操作,提高生成音频的质量和多样性。
StableAudioOpen目前已经开源,IT之家附上相关链接,感兴趣的用户可以在HuggingFace上试用。据说它使用了来自FreeSound和FreeMusicArchive等音乐库的486000多种采样进行训练。
StabilityAI公司表示:“虽然它可以生成简短的音乐片段,但并不适合完整的歌曲、旋律或人声”。
StableAudioOpen和StableAudio2.0不同是,前者为开源模型,专注于短音频片段和音效,而后者能够生成最长3分钟的完整音频。
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-06-07 08:45:08
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址:
更多关于音频,生成,模型,文生,音效,音乐的资讯:
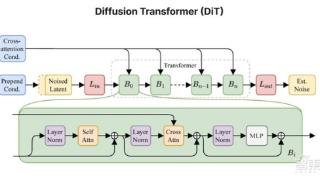
...节。Stable Audio Open是StabilityAI于今年6月推出的开源文本转音频模型,可免费生成长达47秒的样本和音效
2024-07-25 09:22:00
...音效的模型,能够基于视频内容智能合成背景音乐、对话音频及环境音效,其架构如下图所示:CogSound的核心技术依托于GLM-4V的多模态理解能力,能够精确解析视频中的语义和情
2024-11-09 09:54:00

...动输入的提示词直接为视频配音。没过几小时,另一个AI音频克隆“扛把子”ElevenLabs就发布了文字到音频模型的API
2024-06-21 10:53:00

...成模型 Movie Gen Video , 300 亿参数。最大的基础视频生成音频模型 Movie Gen Audio
2024-10-08 09:51:00

...一款搞视频生成的模型VideoPoet,不仅能支持根据视频加入音频效果,允许交互编辑,更重要的是,VideoPoet现在可以生成更长的视频了
2023-12-22 14:45:00

...0P或1080P分辨率,24帧每秒。此外,生成扩展功能也能用于音频剪辑,它可以将视频中的音效或环境背景音扩展最多十秒钟,但不会延长语音对话或音乐。2. 文生视频:可仿照摄像机
2024-10-17 09:52:00
...式AI工具,该工具能够帮助用户通过文本提示创作音乐和音频。据Meta公司介绍,AudioCraft主要包含三个核心组件
2023-08-03 21:23:00

...gion:ark+cn-beijing/experience/vision?projectName=default&
2024-09-30 09:51:00
...作或 AI 工程技能。在 Clapper 中,你无需直接编辑视频和音频文件序列,而是通过调整高级、抽象的概念,如角色
2024-08-14 09:39:00
更多关于科技的资讯:







