- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
huggingface公布“smollm”小语言模型家族
7月20日消息,如今小语言模型开始升温,许多厂商开始推出适用于手机等轻量级设备的“小模型”,本周HuggingFace便公布了“SmolLM”小语言模型家族,其中包含1.35亿、3.6亿及17亿参数模型。

据介绍,这些模型号称是以精心策划的高质量训练数据集训练而成,号称在Python程序编写性能上相当强大,团队指出他们重点优化了模型所需的RAM用量,“即使是在6GBRAM的iPhone15上也能运行”。
在训练方面,HuggingFace团队首先建立了一款名为SmolLM-Corpus的数据集(数据集地址点此访问),该数据集主要包含Python教学内容Python-Edu、Web教育内容FineWeb-Edu以及使用Mixtral-8x7B-Instruct-v0.1和Cosmopediav2两款模型生成的常识内容,token量总计6000亿。此后HuggingFace团队便使用SmolLM-Corpus数据集训练了“SmolLM”小语言模型。
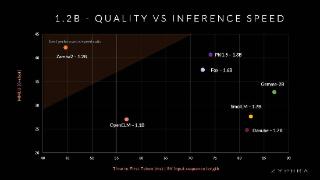
HuggingFace团队将开发出的SmolLM模型与相同参数量的其他模型进行了基准测试,其中SmolLM-135M在多项测试中超越了小于2亿参数的其他模型;而SmolLM-360M的测试成绩优于所有小于5亿参数以下的模型,不过某些项目逊于Meta刚刚公布的MobileLLM-350M;SmolLM-1.7B模型则超越了所有参数量小于20亿参数的模型,包括微软Phi-1.5、MobileLLM-1.5B及Qwen2。

以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-07-21 08:45:04
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址: