- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
科学家提出大模型分子交互学习框架,已在400多万分子对中验证
设想一下:对于“某个新型药物分子注入到小白鼠体内,会产生怎样的交互”这一问题,假如不需要复杂的临床实验设计,也不需要繁琐的重复实验验证。
仅仅将药物和环境中包含的多个分子告诉类似于 ChatGPT 的聊天机器人,它就可以快速、准确地将该药物会带来的影响一五一十地告诉科学家,那么必将极大降低科研人员的时间成本、以及相关厂商的资源成本,为更快、更精确地发现药物提供助力。
前不久,中国科学技术大学博士生方俊峰和所在团队开发的首个统一的多模态大语言模型分子交互学习框架——MolTC(Molecular inTeraction Modeling enhanced byChain-of-thought theory),为解决上述问题带来了新的曙光。
目前,在多个数据集的 4000000 多个分子之中,MolTC 框架的可靠性已经得到验证。“诚然这一问题目前看上去依旧是是天方夜谭、遥遥无期。但是,我们的工作在这千里之行中只是往前迈进了一小步。”方俊峰说。

图 | 方俊峰(来源:方俊峰)

MolTC:能够高效建模分子图信息
研究中,方俊峰等人重点研究了分子关系学习、药物对交互、溶液-溶剂交互(Solution-solvent Interaction,SSI)等要素,理解和建模了分子对的交互作用,通过此设计了这款统一的多模态大语言模型分子交互学习框架——MolTC。
通过利用图编码器(Encoder)和映射器(Projector),MolTC 可以高效地建模分子图信息。
此外,为了加强数据间的信息共享,以及实现统一的分子交互学习,课题组提出了多层级思维链(Multi-hierarchical Chain-of-thought)的概念,来优化大模型的思考范式和训练范式。
同时,该团队还采用一个分子交互任务间的动态参数来共享策略,以实现预测效率和预测精度的双赢。
目前来看,这款框架最直观的应用在于:能被用来构建一个更全面的、无需深度学习基础和生化知识先验的统一型分子交互输出平台。
这意味着,通过进一步地收集和吸纳数量更多的、覆盖面更广的分子交互任务,MolTC 可以显式地、高效地学习通用的分子交互底层范式和机制,从而更精确地把握隐藏的分子关系。
这不仅颠覆了传统深度学习模型只能同时适配少量任务的局面,也弥补了传统大模型只能以内部隐式的方式来学习分子交互规律的短板。
同时,凭借显式的、统一的架构,MolTC 可以在少样本、甚至零样本的交互任务中,仍能保持精准高效的输出。
另一方面,当前大多数的分子交互模型,不管是基于传统的深度学习模型,还是基于经典大模型微调后的模型,都需要使用者具备一定的深度学习基础和生化知识先验,来通过特定的数据集去训练模型。
但是,一旦 MolTC 框架集成了更全面的交互任务,凭借其在零样本任务上优越的性能,它可以直截了当地给出交互结果。同时,MolTC 框架还可用于多分子交互任务的分析与建模。
那么,到底是基于怎样的背景让方俊峰等人启动了本次研究?
近年来,凭借丰富的知识储备和优秀的推演能力,大模型已成为实现分子关系高效学习的重要工具。然而,虽然当前范式成绩斐然,其仍然面临一定的问题。
具体来说,当前的范式过于依赖文本数据比如分子的 SMILES(Simplified molecular input line entry system,简化分子线性输入规范)信息,因此未能深入挖掘分子图中所蕴含的丰富的结构信息。
更为关键的是,当前缺乏一个统一的分子交互学习框架,这一点阻碍了人们从不同数据集中学习并提炼关键信息。
而这对于包含少量标签数据的任务是灾难性的。以溶液-溶剂交互为例,包含 100000 对分子的 SSI 数据集 CombiSolv,可以很好地用于训练当前的主流框架。
但是,由于缺乏统一范式所导致的底层分子交互机制无法共享,很多数据量较少的 SSI 数据集比如 FreeSolv,哪怕采用了基于 LoRA 等优秀的微调策略,也会由于高度的过拟合风险而无法支撑大模型的训练。
更糟糕的是,缓解这一问题需要通过生化实验来生成标签数据,这一过程十分消耗时间和资源。
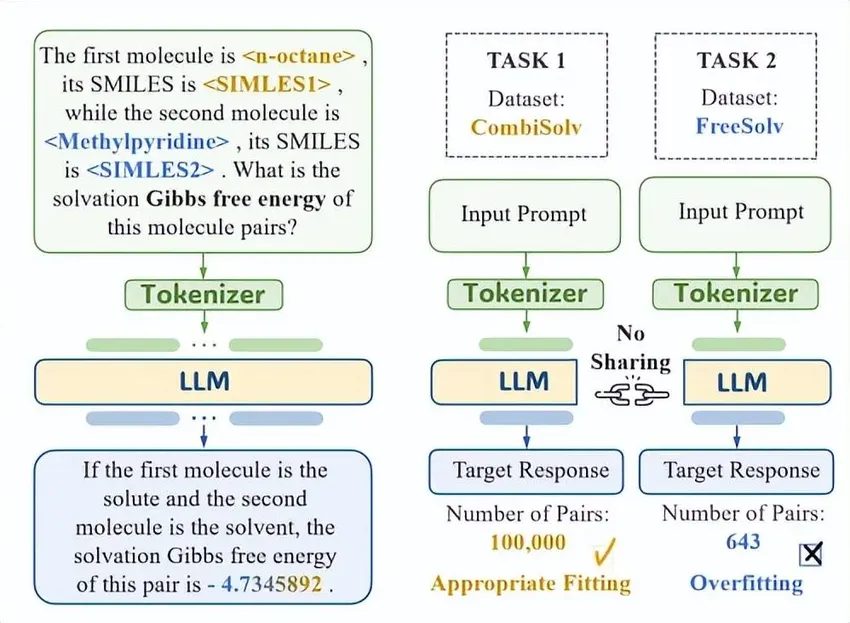
图 | 当前基于大模型的分子交互任务的通用范式(来源:arXiv)
方俊峰等人注意到:近年来,大模型在生化领域取得了多个重大突破,比如可以预测蛋白质结构的 AlphaFold2 等。
这些助推基础科学研究的、可以造福人类的 LLM4Science 工作让人十分震撼。同时,对于 Biochemical LLM 领域也有着举足轻重的现实意义。
一开始,他们瞄准是以生化大模型为基础的框架优化。其认为这些主流的范式和生化任务,大部分都是单分子相关的任务,比如分子性质预测、IUPAC 命名等。
后来,他们发现在很多情况下:大量的分子性质比如溶解产生的吉布斯自由能,无法独立于分子交互而单独存在。
而人们往往更关心的是分子在交互中扮演的角色,而非单个分子自身的性质。以药物分子性质为例,药物分子对的交互,对于药物研发至关重要。
同时,人们也非常关心药物对于人体的影响,即药物分子和人体环境中特定分子的交互,而非药物本身复杂的生化性质。
与之(分子交互的重要性)相对的,课题组发现目前大多数关注分子交互任务的大模型,都仅仅关注于单个或少量分子的交互任务。
而统一的大模型分子交互学习范式,依然处于空白地带。该团队认为,统一的学习范式能够充分利用底层分子交互机制之间的共享,更透彻地调动大模型的推理能力和知识储备能力。

大模型可能是一个“慢热型的 i 人”
基于上述原因,课题组打算开发一款统一的大语言模型分子交互学习框架。
研究期间,他们面临的第一个挑战是:如何高效地提取交互中两个分子的信息,并让大模型理解它们?
后来他们发现,目前那些用于建模分子交互的大模型,大部分依赖的是分子的文本信息,鲜有大模型能够深入挖掘分子图中所蕴藏的结构信息。
Q-Formers(Querying Transformers)网络架构,是一个轻量级的 transformer,在“视觉-语言”的多模态研究中,它一直有着“高光表现”。
以此为启发,课题组使用两个图神经网络(GNN,Graph Neural Network)编码器来获取分子对的表征,并通过 Q-Formers 将其映射到大语言模型的输入空间中。
这一设计为大模型安装了一个可以清楚洞察的“眼睛”,让其能以高效、准确的方式,去理解生化分子之间的交互。
然而,他们却发现:相比两个单分子性质的分析,分子对交互性质的分析难度,呈现出指数级的增长。
具体来说,必须在准确理解两个分子性质的基础上,针对不同的交互目标,分别地提取特定的关键子结构,只有这样才能完成交互建模和交互分析。
对于传统大模型来说,它们本身就不擅长处理定量估值任务,因此很难直接根据输入分子对,来给出交互性质的精确数值(如发色团溶解任务中的最大吸收波长)。
方俊峰表示:“当时,大模型已经能够很好地完成定性任务,但是一直无法精确地给出分子交互的数值。”
于是,他们尝试修改大模型的架构,测试了很多不同的模型架构,结果都是无功而返。
“后来,我们在吃饭的时候,团队中的张帅提出,大模型可能是一个‘慢热型的 i 人’,让它直截了当地说出自己的想法可能太强人所难了。
不如给它一个逐渐表达的过程,我们可以像一个心理辅导老师或多年好友一样倾听它,引导它说出来。”方俊峰说。
受此启发,他们测试了多层级思维链的形式,借此提高了定量分析任务的精度。
具体来说,让处于上层的思维链指导 MolTC 的预训练过程,从而优先识别、并按照次序给出分子的关键生化性质,从而提升分子交互的预测准确率。

图 | 预训练阶段的提示词和预期回复的设计(来源:arXiv)
期间,预训练阶段的数据来自 Drugbank 和 PubChem,它们都是包含分子-性质对的权威生化数据库。
此外,为让 MolTC 框架能够适用于多种应用场景,他们针对上述数据库中的分子进行随机组合,借此构造了横跨多个领域的不同分子对。
同时,在涉及到更复杂、更棘手的定量分子交互任务时,在下层的思维链指导之下,MolTC 会优先为目标数值预估一个大致范围,然后逐步将其细化到一个精确的值。

图 | 以溶液-溶剂交互任务为例,其提示词的设计如图所示(来源:arXiv)
这一多层级思维链的方式带来的好处是,能让 MolTC 有条不紊地思考和推演,以小步快跑的方式完成分子交互,特别是能够完成定量分子交互的精确预测。
同时,课题组从 MolTC 这一框架中,偶然发现采取“先给区间,再逐步收敛”的方式,也能助力于提高大模型定量输出任务的准确性。

图 | 基于多层级思维链的分子交互学习范式(来源:arXiv)
至此,MolTC 的基础框架和训练范式基本搭建完毕。然而,在实验中他们发现,由于两个分子输入至大模型之前所经历的图编码器(Encoder)和映射器(Projector)结构完全一致,大语言模型经常会混淆两个分子的性质。
即在回答分子 2 的性质的时候,它会错误地给出分子 1 的性质。为了解决这一问题,他们意识到只将分子图信息给到大模型是不够的,仍然需要额外引入分子的信息进行辅助。
于是,他们在大模型的输入端,额外引入两个分子的 SIMLES 形式,从而让 MolTC 能够清楚地辨别两个分子的输入顺序。
完成上述设计之后,该团队终于如愿以偿地看到,MolTC 在各个分子交互任务中能够取得不错的效果。
方俊峰说:“但是,没过多久我们就再次失望了。我们发现为了实现统一的学习框架而不断加入新的数据集时,MolTC 的预测精度下降得十分明显。”
后来,该团队的吴畅察觉到:底层的交互的机制虽然相似,但是具体的表现形式不尽相同。同时,各个交互数据集的侧重点也各有不同。
因此,如何从分子交互数据集之间的共性,提炼出通用的底层交互机制,并排除各个数据集的冗余信息的干扰,是课题组面临的另一个挑战。
而只有解决这一挑战,才能构建统一的分子交互学习框架。为解决这一问题,他们验证了分子交互任务的以下属性:
其一,验证交互中分子角色的重要性。其二,验证交互中分子顺序的重要性。其三,验证分子角色/顺序带来的特征重要性的差异。
然后,他们引导 MolTC 在学习各个分子性质的时候,根据角色和顺序来为分子创建独特的编码。
而为了 MolTC 让能够很好地学习到这种差异性,他们引入了动态参数的共享策略。
最终,课题组在横跨多个分子交互领域、累计 12 个分子交互数据集的 4000000 多个分子对上,验证了 MolTC 的有效性,证明 MolTC 可以高效、准确地预测出目标分子交互。
日前,相关论文以《MolTC:语言模型中的分子关系建模》(MolTC:Towards Molecular Relational Modeling In Language Models)为题发在 arXiv[1],方俊峰是第一作者,中科大教授 Wang Xiang 担任通讯作者。

图 | 相关论文(来源:arXiv)
后续,他们打算进一步增加 MolTC 的训练数据,打造一个真正可以实现“统一”的分子交互学习框架。
另外,课题组发现虽然 MolTC 在小分子任务上表现十分突出,但是当任务涉及到大分子交互时,其表现偶尔会所有不尽人意。
因此,他们计划在大模型接口的前端额外嵌入一个信息压缩模块,利用深度学习可解释领域常用的“图信息瓶颈”(GIB, Graph Information Bottleneck)等技术,对输入的大分子信息进行压缩,借此排除冗余信息的干扰,从而进一步提高 MolTC 框架的适用范围。
参考资料:
1.https://arxiv.org/abs/2402.03781
运营/排版:何晨龙
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-03-07 19:45:02
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址:













